4. 数据安全之攻击¶
在过去的数十年中,人工智能已经迅速渗透到我们的日常生活中,在包括计算机视觉、自然语言处理、语音识别等多个关键领域取得了巨大的成功。然而,人工智能模型的训练需要大量数据和计算资源。因此,工业界和学术界在训练模型时使用外包数据、第三方机器学习平台或者预训练模型已经成为一种惯例。这种便捷的开发方式可以让研究人员快速的开发一个可用的人工智能模块并迅速投入使用,而不需要了解具体所使用的训练数据,但这也带来了很大的安全隐患。正因数据的完整性和准确性对机器学习算法正确运行的重要性不言而喻,数据也就自然成为攻击者的主要攻击目标之一。本章从数据投毒、隐私攻击、数据窃取和篡改与伪造四个角度介绍现有机器学习范式下数据所面临的攻击。
4.1. 数据投毒¶
数据投毒(也称投毒攻击)是一种训练阶段的攻击,其通过污染训练数据来干扰模型的训练,从而达到降低模型的推理性能的目的。投毒攻击的一般流程如图 图4.1.1 所示。在实际场景中,投毒者可以通过两种方式实施投毒攻击,即被动攻击和主动攻击。被动攻击是指攻击者可通过在线社交媒体上传有毒数据到网上,等待受害者利用网络爬虫下载使用;主动攻击则可以直接将有毒数据发送到数据集收集器中(如聊天机器人、垃圾邮件过滤器或用户信息数据库)。研究机构对28家公司的调查问卷显示数据投毒是工业界最担心的人工智能安全问题 (Kumar et al., 2020) 。
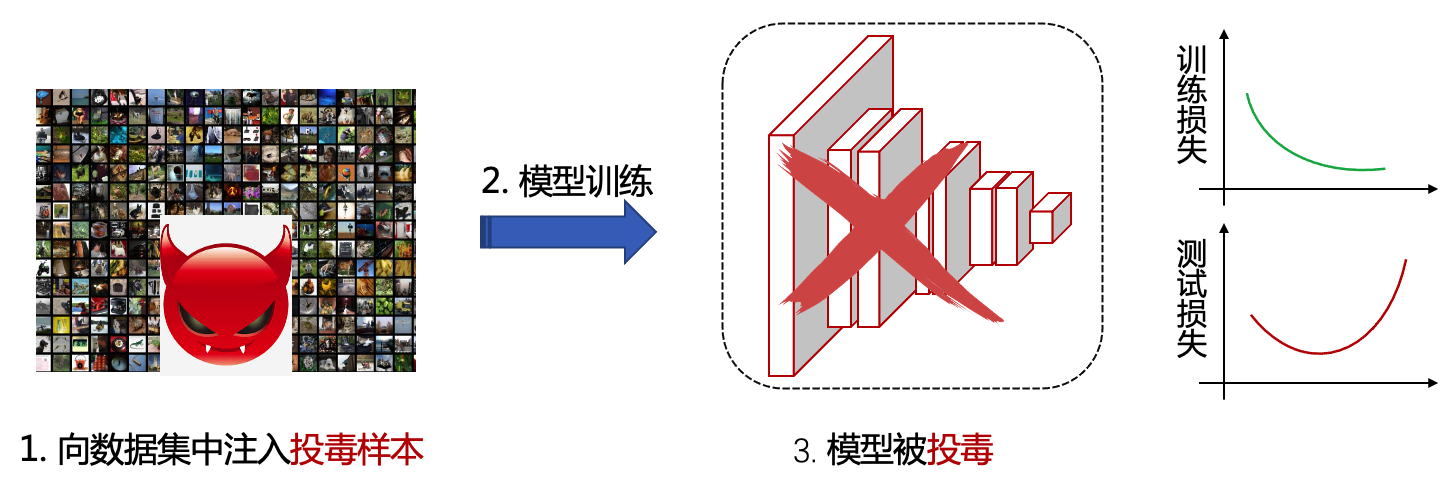
图4.1.1 投毒攻击示意图¶
数据投毒工作可以追溯到1993年Kearns和Li (Kearns and Li, 1993) ,他们在PAC(probably approximately correct)学习设置下研究了如何在有恶意误差数据存在的情况下进行模型训练。 2006 年,Barreno等人 (Barreno et al., 2006) 揭示了通过恶意训练人工智能系统可以混淆网络入侵检测系统(intrusion detection system,IDS),使其在推理阶段对特定攻击不做拦截。2008年,Nelson等人 (Nelson et al., 2008) 提出了针对垃圾邮件过滤器(spam filter)的投毒攻击,通过错误标记1%的训练数据成功破坏了朴素贝叶斯(naive Bayes)分类器的垃圾邮件过滤功能。2012年,Biggio等人 (Biggio et al., 2012) 正式提出了投毒攻击的概念。他们认为投毒攻击指通过将一小部分毒化数据注入训练数据或直接投毒模型参数,进而损害目标系统的功能的攻击。
数据投毒可大致分为六类:标签投毒攻击、在线投毒攻击、特征空间攻击、双层优化攻击、生成式攻击和差别化攻击。
4.1.1. 标签投毒攻击¶
模型训练是一个对训练样本进行迭代,使其能够一步步靠近标签的过程。所以正确的标签对正确的模型训练至关重要,而对攻击者来说也是如此,攻击训练过程所使用的标签是最直接一种投毒方式。这种攻击方式被称为标签投毒攻击(label poisoning attack),其通过混淆样本与标签之间的对应关系来破坏模型的训练。例如,标签翻转攻击(label flipping,LF)将部分二分类数据的\(0\)/\(1\)标签进行随机翻转,使\(0\)标签对应数据在训练中靠近假标签\(1\)而\(1\)标签对应数据靠近假标签\(0\)。可以看出,此类投毒攻击需要很强的威胁模型,要求投毒者可以操纵训练数据的标注或使用。在二分类问题下,随机标签翻转攻击可形式化表示为:
其中,\(y\)是原始标签,\(1-y\)可以在0-1分类问题下进行类别的翻转,\(\text{random}(\cdot)\)表示随机选择函数,适用于多分类问题。
除了随机选择样本翻转,我们还可以有选择性地对一部分数据进行翻转以最大化攻击效果。Biggio等人 (Biggio et al., 2012) 在随机标签翻转攻击的基础上,通过优化方法寻找部分易感染样本进行标签翻转,可以成功损害鲁棒训练的目标。Zhang等人 (Zhang and Zhu, 2017) 从博弈论的角度证明了标签翻转攻击对基于共识(consensus-based)的分布式支持向量机(distributed support vector machines,DSVM)同样有效。形象的理解,标签投毒类攻击是一种“指鹿为马”攻击,明明是物体A却非要说成是物体B,从而达到混淆视听的目的。
4.1.2. 在线投毒攻击¶
在线投毒攻击,也称\(p\)-篡改攻击(\(p\)-tampering attack)是指在在线学习过程中对训练样本以一定概率\(p\)进行投毒以此削弱模型推理能力的攻击。在线投毒攻击假设攻击者可以对训练样本进行在线的修改、注入等,但对标签不做改动。 最早将\(p\)篡改攻击用于数据投毒的是Mahloujifar和Mahmoody (Mahloujifar and Mahmoody, 2017) ,他们以在线训练中的一段训练数据为原子,对其中比例为\(p\)的数据施加噪音来进行偏置,进而对模型在推理阶段的功能进行干扰。形象的理解,\(p\)篡改攻击是一种“暗度陈仓”攻击,在不改变类标的情况下(高隐蔽性),以一定概率偷偷修改样本,使数据分布产生偏移。
Mahloujifar等人 (Mahloujifar et al., 2019) 后续将单方 \(p\)-篡改攻击可以扩展到\((k,p)\)-篡改攻击,其中\(k\in\{1,2,\cdots,m\}\)表示\(m\)个参与方中被攻击者控制的个数。\((k,p)\)-篡改可以高效的完成攻击,且不需要修改标签,是一种只依赖当前时刻样本的高效在线数据投毒攻击。
4.1.3. 特征空间攻击¶
特征空间投毒(feature space poisoning)攻击通过修改毒化样本的深度特征来完成攻击。通过基于替代模型的深度特征修改,特征空间攻击几乎可以随意修改样本与类别之间的对应关系,即能让一个类别为A的样本跟任意非A类别的深度特征匹配。特征空间攻击有三个隐蔽性优势。首先,在特征空间进行对应关系的修改并不需要修改标签,具有很高的隐蔽性。其次,特征投毒可以基于优化方法通过对输入样本的轻微(微小)扰动完成,并不需要明显的投毒图案,因此可轻易躲过人工审核。第三,特征空间攻击通常只影响模型对特定目标样本的分类,而不影响非特定目标样本,故而很难被检测出来。毒化数据的影响通常在模型部署后才会显现出来。
2018年,Shafahi等人 (Shafahi et al., 2018) 提出了一种经典的特征空间投毒攻击方法:特征碰撞攻击(feature collision attack)。特征碰撞攻击是一种白盒数据毒化方法,其通过扰动部分基类(base class)训练数据,使其在特征空间下趋于目标类(target class),从而诱使模型在训练过程中产生误解。特征碰撞攻击最初是为攻击单个目标样本而设计的,所以也被称为“有目标”攻击,攻击多个样本则需要重复多次同样的攻击过程。具体而言,攻击者巧妙的使有毒基类数据点在特征空间中靠近目标类样本,从而诱使目标模型在推理阶段将目标类测试样本误分为基类类别。
特征碰撞攻击的优化目标定义如下:
其中,\({x}_p\)为毒化样本,\({x}_t\)为目标测试样本,\({x}_b\)为训练数据中一个基类样本,\(f\)表示目标模型,\(f(\cdot)\)为模型的输出,\(\beta\)为超参数。上式中,第一项使毒化样本接近攻击目标类别\(t\),达成攻击目的;第二项\(\parallel{{x}_p-{x}_b}\parallel^2_2\)控制毒化数据与基类数据相似,使二者在视觉上无明显差异,起到伪装效果。通俗的理解就是,让\({x}_p\)看上去像\({x}_b\)而特征和预测类别像\({x}_t\),起到“声东击西”的目的。后续很多隐蔽性数据投毒算法都是基于此思想,只是在优化方法上略有不同。
在特征碰撞攻击中,目标模型通常是在干净数据上预训练的模型,而投毒攻击发生在后续的模型微调过程中,主要用于攻击基于公开预训练模型的迁移学习。由于迁移学习冻结特征提取器而只微调最后一层的线性分类器,所以特征碰撞攻击对迁移学习很有效,有时毒化单张图像就可以成功攻击。然而,特征碰撞攻击也存在一定的局限性。首先,特征碰撞攻击需要攻击者掌握目标模型,这是很强的威胁模型假设。其次,一旦目标模型又通过其他干净数据再次微调,那么特征攻击效果会大大降低。因此,端到端训练或逐层微调对特征碰撞攻击具有显著的鲁棒性。
Zhu等人 (Zhu et al., 2019) 在2019年提出了基于净标签的凸多面体攻击(convex polytope attack,CPA)以提高特征空间攻击的迁移性。与特征碰撞攻击的单样本混淆策略不同,凸多面体攻击尝试寻找一组毒化样本将目标样本包围在一个凸包内。凸多面体攻击的优化目标如下:
其中,\({x}_p\)为毒化样本,\({x}_t\)为目标测试样本,\({x}_b\)为训练数据中一个基类样本;一组预训练模型的集合被定义为\(\{f^{(i)}\}^m_{i=1}\),\(m\)是集合中模型的数量;\(\{{x}^{(j)}_p\}^k_{j=1}\)是针对\({x}_t\)设计的\(k\)个“包围”样本,约束\(\sum^k_{j=1}c^{(i)}_j=1, c^{(i)}_j\geq0\)指“包围”投毒样本的权重都大于0且加和为1;添加扰动的上界被定义为\(\epsilon\)。凸多面体攻击在特征空间中构建了更大的“攻击区域”,从而增加了迁移攻击成功的可能性。当在多个中间层中实施凸多面体攻击时,迁移性会更大。形象的理解,凸多面体攻击是一种“四面楚歌”攻击,从不同角度对特征子空间进行围攻,从而使投毒数据在从头训练设置下也能起作用。
4.1.4. 双层优化攻击¶
最新的研究往往通过双层优化的方式去实现数据投毒,其也可以与其他攻击方式结合产生更大效益。实际上,优化的思想在数据投毒中早已存在,比如通过优化方法找出最适合标签投毒的数据集或者找到最有效的数据投毒方案。早在2008年,Nelson等人 (Nelson et al., 2008) 便在其工作中通过优化产生能最大化合法邮件有害得分的电子邮件,并用来毒化训练数据。2012年,Biggio等人 (Biggio et al., 2012) 同样也使用了优化方法来找到可以最大化分类误差的样本。上述两种方法都是利用梯度上升的迭代算法来一步步计算出最优解决方案,并更新迭代出最终目标模型。为了统一概括数据投毒的优化问题,Mei和Zhu:raw-latex:cite{mei2015using}`在2015年正式提出了“有毒数据构建+目标模型更新”的双层优化(bi-level optimization)问题,并证明利用梯度可以有效地解决此双层优化问题。此后,数据投毒攻击便进入了基于双层优化问题求解的时代,研究者提出了很多更有效、更快速、亦或更便捷的数据投毒攻击方法。
双层优化攻击的核心是一个最大最小化问题。双层优化攻击的流程大体上是这样的:(1)攻击者首先将投毒攻击问题转化为一个优化问题以便找到全局最优值;(2)攻击者使用常见优化算法(如随机梯度下降)在相应的约束下检索解决方案。 数据投毒对应的双层优化问题可形式化如下:
其中,\(D\)、\(D_{\text{val}}\)及\(D_{p}\)分别表示原始训练数据、验证数据已及有毒数据,\(\mathcal{L}_{\text{in}}\)和\(\mathcal{L}_{\text{out}}\)分别代表内层和外层的损失函数。外层优化的目的是生成可以最大化(未受污染的)验证数据集\(D_{\text{val}}\)在目标模型\(\theta'\)上的分类错误的有毒数据。内层优化的目的是通过迭代更新得到数据投毒后的目标模型,即目标模型会在有毒数据集\(D\cup D_p\)上迭代更新。由于目标模型参数\(\theta'\)是由有毒数据集\(D_{p}\)来隐性决定的,所以在外层优化中,我们用函数\({\mathcal{F}}\)来表述\(\theta'\)和\(D_{p}\)之间的联系。整个双层优化的过程可以描述为,每当内层优化达到局部最小值,外层优化会用更新后的目标模型\(\theta'\)来更新有毒数据集\(D_{p}\),直到外层优化的损失函数\(\mathcal{L}_{\text{out}}( D_{\text{val}},\theta' )\)收敛。
双层优化攻击是一种破坏型攻击,因为其攻击目标是让目标模型发生错误分类。当然,双层优化攻击也可以是操纵型的,即让目标模型将目标数据误分类为特定类别(需要预先指定)。在这种情况下,双层优化就变成了一个最小最小化问题,定义如下:
其中,\(y_{\text{adv}}\)是攻击者预设的错误类别。而此时外层优化的目的是生成可以最小化目标模型\(\theta'\)在目标数据上的分类错误的有毒数据。上面的双层优化框架很好地概括了数据投毒与目标模型更新之间的关系,通过代入不同的目标函数、攻击目标及训练数据集,几乎所有数据投毒攻击场景都可以用这个框架实现。
解决双层优化问题的一种思路是通过迭代算法来步步逼近全局最优解。而基于梯度的攻击又可以将训练数据往目标梯度方向扰动进行数据毒化,直至毒化数据达到最优效果。在\(\mathcal{L}_{\text{out}}\)可微的情况下,梯度可以通过链式法则(chain rule)计算如下:
其中,\(\nabla_{D_p}{\mathcal{F}}\)表示\({\mathcal{F}}\)关于\(D_p\)的偏导数。第\(i\)次迭代的毒化数据\(D_p^{(i)}\)可以通过梯度上升更新至\(D_p^{(i+1)}\),形式化定义如下:
其中,\(\alpha\)是由攻击者控制的学习率。
上面提到的例子多是针对传统机器学习(或者简单神经网络)的数据投毒攻击,他们隐性地假设基于梯度的内层优化可以被完美解决。然而,对于深度神经网络来说,其梯度有可能爆炸或消失,因此,针对深度学习的双层优化攻击需要特殊的梯度计算方式。 Muñoz-González等人 (Muñoz-González et al., 2017) 利用”反向梯度法”来更高效稳定地计算内部优化的梯度。作者使用逐步梯度下降法近似求解内层优化问题,而每步梯度下降都会反向传播至外层优化及目标函数进行求解,经过数次迭代最终得到满足双层优化目标的毒化数据。然而基于随机梯度下降法的微分对内存来说是一个非常大的负担,所以该毒化数据制造方法是单个进行而不是分批次进行的,且只能作用于单层神经网络。
2018年,Jagielski等人 (Jagielski et al., 2018) 将Muñoz-González等人 (Muñoz-González et al., 2017) 的工作进行了扩展,提出了一个专用于回归模型的数据投毒及防御的理论优化框架。Huang等人:raw-latex:cite{huang2020metapoison}提出的MetaPoison采用集成的方式,利用:math:m个模型和:math:`K-step内部最小化来求解公式[equ:chap4bileveloptTG]。具体来说,对每个模型在毒化数据上进行\(K\)步基于SGD的梯度下降,然后计算并存储外部最小化对应的梯度(称为对抗梯度),在\(m\)个模型上计算完毕后累积得到平均对抗梯度,之后使用平均对抗梯度更新毒化样本。当达到一定的训练周期后,需要重新初始化\(m\)个模型的参数,以增加探索(防止因模型收敛过快而导致毒化样本探索不够)。
相比之前的方法,MetaPoison是净标签数据投毒(clean-label data poisoning)领域的一个重要改进。其数据毒化过程更加通用,无论是破坏型还是操纵型攻击目标都可达成,生成的毒化数据可以在整个训练过程中都对目标模型有影响,而且不会对某个代理模型过拟合。此外,MetaPoison还做到了毒化数据的跨模型和训练设置迁移,即MetaPoison生成的毒化数据可投毒其他训练设置、网络架构未知的模型。MetaPoison甚至成功毒化了工业级服务,即Google Cloud AutoML API。而MetaPoison也是第一个在人眼不可察觉的前提下,可同时攻击微调模型及端对端模型的数据投毒方法。
2020年,Geiping等人 (Geiping et al., 2021) 对MetaPoison攻击做了进一步改进,提出了Witches’ Brew攻击方法,使得此类投毒攻击达到工业规模。Witches’ Brew攻击引入“梯度对齐”的概念,使毒化目标函数与对抗目标函数具有一致的梯度,也就是说,使模型在毒化样本和其目标样本上的梯度一致。当这个目标达成时,毒化样本和目标样将对模型产生同样的梯度激活,也就是在训练过程中对模型参数更新起到一模一样的作用,因此训练毒化数据过程中进行的标准梯度下降也会强制使对应目标图像上的对抗性损失降低,进而完成攻击目标(让模型将毒化样本完全当做目标样本来学习)。
4.1.5. 生成式攻击¶
上述数据投毒攻击都在毒化数据生成和使用效率上有所受限,而基于生成模型的生成式攻击(generative attack)则可避免基于优化攻击的高昂计算代价,大大提高毒化数据的生成和使用效率。生成式攻击的核心是生成模型的训练(如生成对抗网络和自动编码器)。生成模型可以通过学习毒化噪声分布进而大规模生成毒化数据。生成式攻击一般需要攻击者知晓目标模型的相关知识,对应灰盒或白盒威胁模型。
Yang等人 (Yang et al., 2017) 提出基于编码器解码器(encoder-decoder)的毒化数据生成攻击。此攻击框架有两个重要的组成模块:生成模型 \(G\)。其毒化数据生成过程可以描述为:在第\(i\)次迭代中,生成模型产生毒化数据\({x}_p^i\);攻击者将此时的毒化数据注入到训练数据中,令目标模型的参数从\(\theta^{( i-1 )}\)更新为\(\theta^{( i )}\) ;攻击者进一步评估目标模型在验证集\(D_{\text{val}}\)上的表现,并以此为依据引导生成模型的进一步优化;攻击者更新生成模型并进入下一迭代。此迭代过程可形式化表示如下:
其中,\(\theta\)表示目标模型\(f\)的原始参数,\(\theta'\)表示目标模型被数据投毒攻击后的参数。生成式攻击的最终目标是使生成模型\(G\)能够无限生成能降低目标模型\(f\)性能的毒化数据。在此基础上,Feng等人 (Feng et al., 2019) 提出了一个类似的生成模型训练方式,引入伪更新(pseudo-update)步骤来更新生成模型 \(G\)和\(G\))所导致的生成模型训练不稳定的问题。
除了自动编码器(autoencoder),生成对抗网络(GAN)也可以用来生成毒化数据。例如Muñoz-González等人 (Muñoz-González et al., 2019) 提出的pGAN攻击,其由生成器 \(G\)及分类器(即目标模型\(f\))三个子模型组成。鉴别器\(D\)用于区分毒化样本与干净样本,而生成器\(G\)旨在生成高效的毒化样本以最大化目标模型\(f\)的分类误差,同时让鉴别器\(D\)无法区别毒化样本与干净样本。这种对抗博弈使得生成式攻击可以在攻击强度和隐蔽性之间做出权衡,更灵活地应对不同风险级别的人工智能模型。
4.1.6. 差别化攻击¶
上述几类攻击方法在投毒的过程中随机选取少量训练样本进行毒化,可以被认为是一种无差别化攻击。然而,研究发现毒化样本的选择会大大影响攻击效果。由此引出了基于样本影响力的差别化攻击(influence-based attack)。基于样本影响力的投毒攻击通过选择影响力大的样本来投毒,以此来提高攻击的强度。单个样本对模型性能的影响可以定义为:
其中,\({x}\)表示目标样本,\(y\)表示样本标签,\(\hat{\theta}\)表示移除样本\({x}\)后所得到的目标模型的参数,\(D_{\text{val}}\)表示验证数据集,\({\mathcal{H}}\)为经验风险的海森矩阵(Hessian matrix),即\({\mathcal{H}}_{\hat{\theta}}= \frac{1}{n}\sum_{i=1}^{n}\nabla^2_{\hat{\theta}}L( f_{\hat{\theta}}( {x}_i ),y_i )\)。
Koh等人 (Koh and Liang, 2017, Koh et al., 2022) 首次将影响函数(influence function)应用于梯度计算,并提出了三种有效的近似双层优化方法。首先,他们通过公式 [equ:chap4influence] 来计算删除特定样本对测试损失的影响,进而确定对模型训练影响最大的样本。接下来,以较大影响样本作为毒化目标,继续利用影响函数来产生毒化数据。最后,将毒化数据注入到原始训练数据集中。最终,该方法成功使目标模型将一个特定测试图片错误分类。Fang等人 (Fang et al., 2020) 将基于影响的投毒攻击用在了推荐系统上,攻击者可以通过精心伪造的用户及交互数据投毒推荐系统,使其做出错误推荐。值得注意的是,Basu等人 (Basu et al., 2021)近来提出,由于深度神经网络的非凸(non-convex)损失表面,影响函数并不能有效捕捉深度神经网络中的数据依赖。因此,差别化攻击在深度神经网络中的应用还有待进一步研究。
4.2. 隐私攻击¶
目前针对数据的隐私攻击主要是针对深度神经网络的推理攻击,攻击者在白盒或黑盒威胁模型下试图从模型中推理或逆向出有关训练数据的信息或者训练数据本身。图4.2.1 以医学图像分析场景为例,展示了在白盒和黑盒两种不同威胁模型下的隐私攻击。 我们的个人数据,如自拍照、健康数据、医疗数据、消费习惯、移动轨迹、个人爱好、电话号码、家庭住址等,有可能会在某个地方被用于训练人工智能模型。而通过隐私攻击,攻击者可以获知个人隐私信息,如是否患有某种疾病、是否到过某个地方等。在人工智能技术被广泛应用的今天,隐私攻击无疑是对个人隐私的巨大威胁。 本章将围绕推理类隐私攻击介绍成员推理攻击、属性推理攻击和其他推理类攻击。 专门的数据窃取类攻击会在章节5.3中介绍。
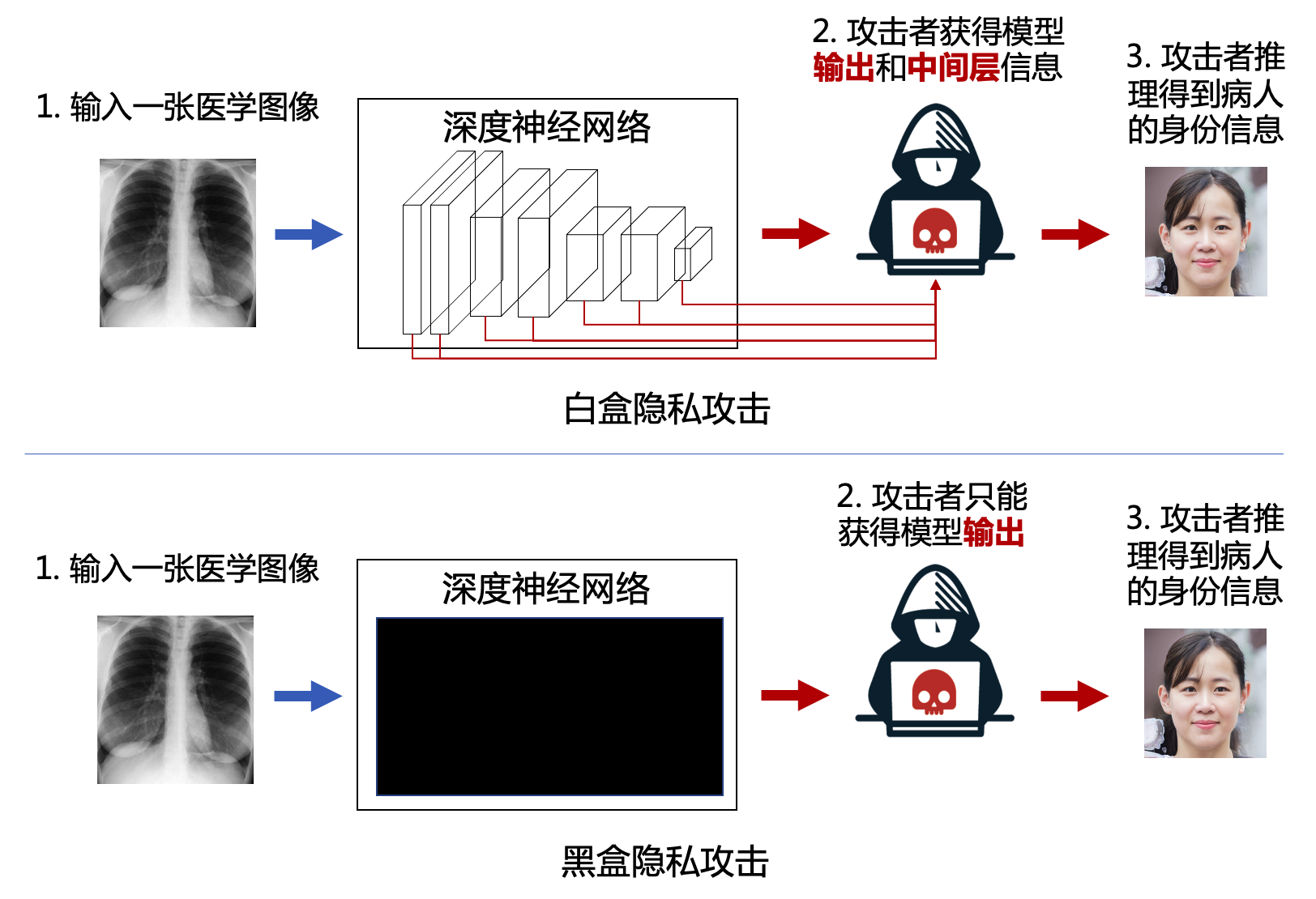
图4.2.1 白盒和黑盒隐私攻击示例¶
4.2.1. 成员推理攻击¶
成员推理攻击(membership inference attack,MIA)的主要思想是利用目标模型在训练数据和测试数据上的不一致性来推理某一样本是否在目标模型的训练数据中。通过判定某个样本是否存在于训练数据集中,攻击者可以进一步猜测样本所属的类别以及其他一些隐私信息,如推断某人是否去过某个地方、是否患有某种疾病等。图 图4.2.2 展示了黑盒威胁模型下的成员推理攻击,此时攻击者只能根据目标模型的输出(比如概率向量)和样本的真是类别信息来判断样本是否存在于训练集合中,而不知道目标模型的参数和中间层结果。
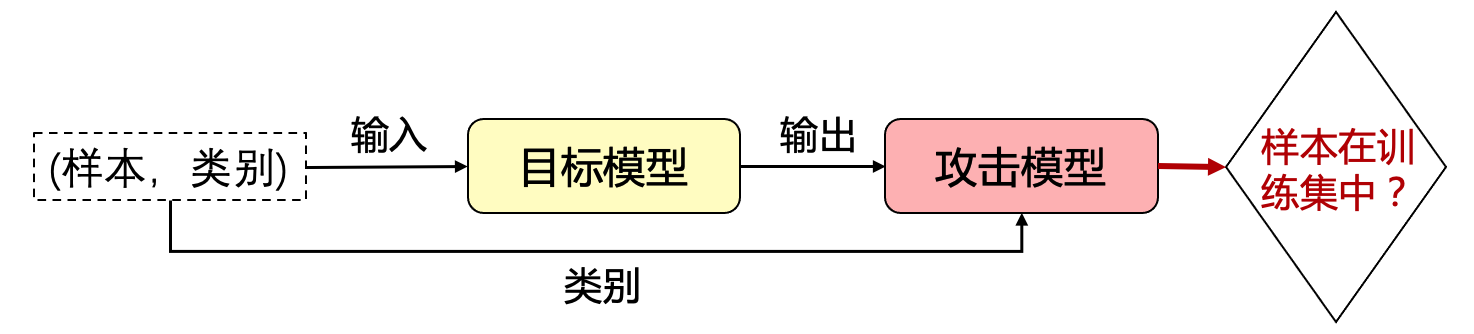
图4.2.2 黑盒威胁模型下的成员推理攻击 []¶
当前成员推理攻击大都针对深度学习模型提出,关于为什么深度学习模型易受成员推理攻击有三个方面的解释。首先,人工智能模型易过拟合训练数据。深度学习模型的高复杂度以及训练数据的有限性导致模型很容易过拟合到训练数据。过拟合的模型一般在训练数据上表现明显优于测试数据,而这种差异往往被攻击者用来进行成员推理攻击。其次,单个样本的变化会影响最终的模型。研究发现,成员推理攻击对决策边界易受单样本影响的模型更容易成功。第三,数据的多样性及取样的局限性。当训练数据不足以充分代表真实数据分布时,模型会对训练过的数据(即训练数据)和未训练过的数据(即测试数据)产生不同的体现。比如,对于分类模型来说,训练样本的平均置信度在训练样本上往往更高。总结来说,模型在训练和测试数据上的泛化差异是导致成员推理攻击存在的主要原因。
成员推理攻击的雏形来自于2008年Homer等人的工作 (Homer et al., 2008) ,其基于基因组数据的公开统计数据集推断某特定基因组是否存于在训练数据集中。 后来,Pyrgelis等人 (Pyrgelis et al., 2018, Pyrgelis et al., 2020)将相关研究拓展至地理位置数据集。但真正让成员推理攻击取得大众广泛关注的Shokri等人 (Shokri et al., 2017) 在2017年提出的工作,他们首次提出对深度学习分类模型的成员推理攻击。在此基础上,后续的工作将成员推理攻击拓展到各类型机器学习模型上,包括分类模型 (Shokri et al., 2017)、生成模型:cite:hayes2019logan、回归模型 (Gupta et al., 2021)、嵌入模型:cite:song2020information等。值得一提的是,Melis等人:cite:melis2019exploiting在2019年提出针对联邦学习的成员推理攻击,引发了系列针对联邦学习“隐私性”的激烈讨论,因为联邦学习理应是一种保护隐私的学习方式。下面三个小节将详细介绍三类经典的成员推理攻击方法。
4.2.1.1. 影子模型攻击¶
影子模型攻击(shadow model-based attack)是2017年由Shokri等人 (Shokri et al., 2017) 提出的成员推理攻击方法,也是首个针对深度学习模型的成员推理攻击方法,其打开了深度学习领域成员推理研究的序幕。 影子模型攻击的思想是将成员推理看做一个二分类(‘成员’或’非成员’)问题。假设攻击者对训练数据的来源分布是有一些先验知识的,即可以从同一个数据分布总池中采样(但与原训练数据不相交)并构建仿数据集的能力。 影子模型攻击大致分为以下三步:
攻击者采样多个影子训练集,并在影子训练集上训练多个可以模仿目标模型表现的影子模型;
根据影子训练集、影子测试集以及影子模型,构建以模型的预测向量输出为样本,以0或1为标签的攻击训练数据集;
在攻击训练数据集上训练得到一个二分类器(称为攻击模型)来进行成员推理攻击。
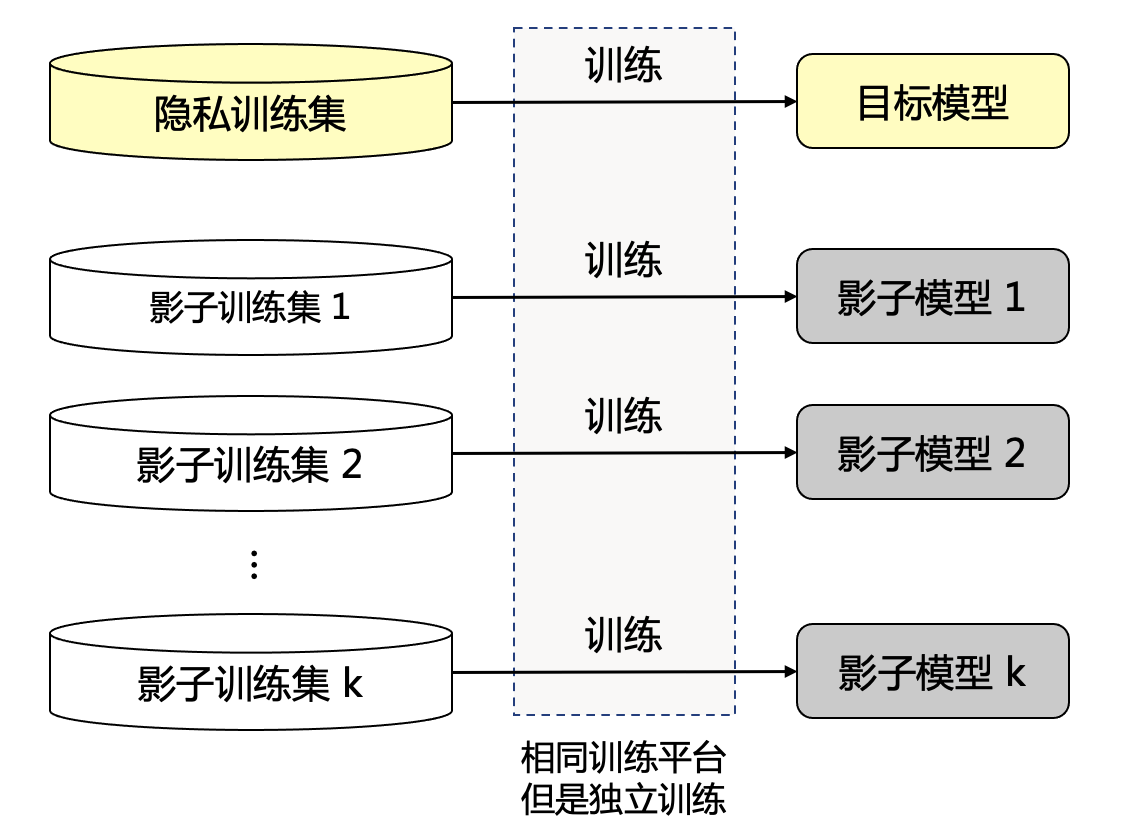
图4.2.3 影子训练集与影子模型示意图¶
图4.2.3 展示了影子训练集和影子模型的概念,影子训练集与隐私训练集来自于相同分布但不重叠,影子模型和目标模型在同一个机器学习平台上相互独立训练。 图 图4.2.4 展示了影子模型攻击中攻击模型(attack model)的构建过程。假设目标数据集为\(D_t\)、目标模型为\(f_t\),影子模型攻击通过独立采样获得与目标数据集独立同分布的\(k\)个影子训练集\(\{D^1_s,\ldots,D^k_s\}\)(\(\forall i\),\(D^i_s \cap D_t=\emptyset\)),并在影子训练集上独立训练得到\(k\)个影子模型\(\{f^1_s,\ldots,f^k_s\}\)。在采样影子训练集的同时,攻击者还采样了\(k\)个影子测试集\(\{D'^1_s,\ldots,D'^k_s\}\)(\(\forall i\),\(D'^i_s \cap D_t=\emptyset\)),通过影子训练集和影子测试集中的样本,我们就可以构建攻击模型的攻击训练集了。将两类样本输入各自对应的影子模型中,得到模型的预测概率向量,如果样本来自影子训练集则将预测概率向量标记为类别“在”(即此样本在影子模型的训练集中),否则将预测概率向量标记为类别“不在”(即此样本不在影子模型的训练集中)。对\(k\)个影子训练集、影子测试集以及影子模型重复上述操作,可以得到最终的攻击训练集\(D_{\text{attack}}\),如:numref:fig_chap4shadowModelMIA 所示。 在攻击训练集上训练即可得到攻击者做成员推理需要的攻击模型,这也就意味着,攻击训练集是一个二分类数据集,攻击模型是一个二分类器,成员推理攻击是一个二分类问题。
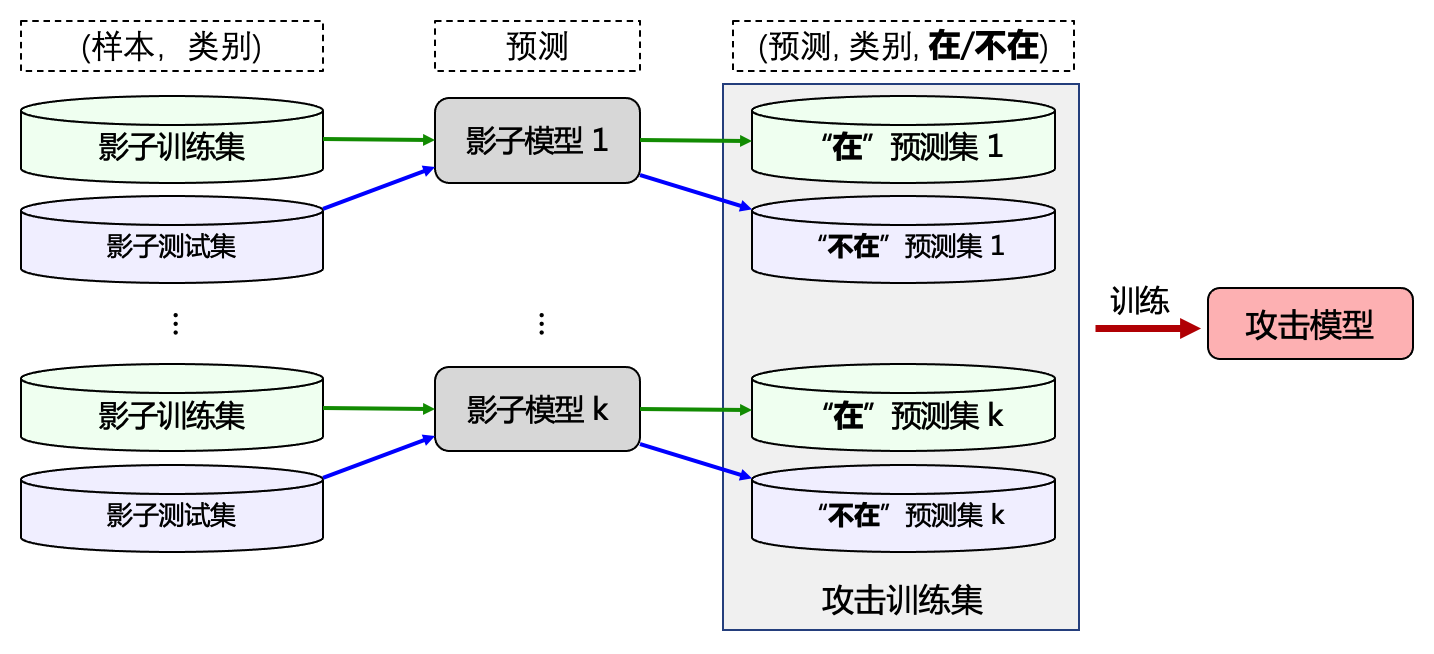
图4.2.4 影子模型攻击¶
影子模型攻击通用于白盒和黑盒威胁模型,虽然根据攻击者所掌握目标模型的信息不同,构建的攻击训练数据集会有一定的差别。在黑盒威胁模型下,攻击者通过API对目标模型进行查询,只能得到对应的预测概率向量;而在白盒威胁模型下,攻击者可以获得中间层的激活信息。下面将以黑盒为主介绍影子模型攻击。
黑盒威胁模型。在黑盒模型下得到的攻击数据集包含以下两个部分:
其中,\({p}({x})\)表示目标模型的预测概率输出,\(D^{m}_{\text{attack}}\)和\(D^{n}_{\text{attack}}\)分别表示“成员”(member)和“非成员”(non-member)类别的数据。下一步是训练攻击模型。假设目标模型\(f_t\)为深度神经网络分类器(模型参数为\(\theta_t\)),那么攻击者可以通过最小化以下经典二分类目标函数,训练得到攻击模型\(f_{\text{attack}}\)(参数为\(\theta_{\text{attack}}\)):
其中,\(n\)表示攻击训练数据集中的样本总数,\(y'_i\)为成员标签(“成员”或“非成员”),\(\mathcal{L}_{\text{BCE}}\)表示二元交叉熵(BCE)损失函数。 通过访问目标模型\(f_t\)的查询API得到任意样本的返回概率向量,再将此向量输入攻击模型\(f_{\text{attack}}\)就可以推理此样本是否属于目标模型的原始训练数据集\(D_t\)。
白盒威胁模型。 Nasr等人 (Nasr et al., 2019) 首先提出了基于白盒威胁模型的成员推理攻击,攻击者对目标模型具有内部访问权限,可以使用更多信息构建攻击数据集。这包括除预测向量及成员类别以外的:任意中间层的激活输出 \(f^{(l)}_t( {x})\)frac{delta mathcal{L}_{text{BCE}}}{delta theta^{(l)}_t }`、输入样本的损失\(\mathcal{L}_{\text{BCE}}\)等。攻击者可以将这些特征拼接为一个大的向量\({v}\),表示为:
而得到的攻击数据集则表示为:
类似地,目标函数则表达为:
Shokri等人 (Shokri et al., 2017) 提出的影子模型攻击需要两个很强的假设:1)攻击者有多个与目标模型结构相同的影子模型;2)攻击者知道训练数据分布。Salem等人 (Salem et al., 2019) 放宽了这两个假设。首先,他们将影子模型的数量缩减至一个,并使用不同于目标模型的网络结构或训练方法来训练这个影子模型。在多个图片数据集上的实验结果表明,宽松假设下的成员推理攻击的成功率有所下降,但在可接受范围之内。紧接着,他们进一步放宽了攻击者所需要掌握的关于目标模型结构和数据分布的先验知识,提出了一种数据迁移攻击。在这种攻击模式下,攻击者用于训练影子模型的数据与目标模型的训练数据来自两个不同的分布。研究发现在基于两个不同分布构建的攻击训练数据集中,成员和非成员数据各自有聚类现象。
Long等人 (Long et al., 2020) 研究了未过拟合人工智能模型的成员推理攻击,发现了除过拟合外成员推理攻击的另一诱因。具体来讲,某些样本在训练阶段会对机器学习模型有着独特的影响,导致模型对这些样本产生了独特的记忆。实验表明,即使在目标模型良好泛化(训练和测试准确率差距小于1%)的情况下,攻击者也可以推断出易感数据样本是否为“成员”。
此外,Nasr等人 (Nasr et al., 2019) 提出的白盒影子模型攻击实际上利用了目标模型的中间层结果以及预测损失作为附加特征来提升攻击成功率。对此,Leino和Fredrikson (Leino and Fredrikson, 2020) 指出白盒影子模型攻击中的模型及数据太过透明,攻击者对目标模型有完全访问权限并掌握很大一部分目标模型的训练数据集,这在实际应用中并不多见,偏离了成员推理攻击的初始假设。对此,作者提出了一种新的白盒假设:攻击者对目标模型有完全访问权限但不知道目标模型的训练数据集。他们认为目标模型的训练数据与数据池之间的特征分布差异可以被用来进行成员推理攻击。
除了分类模型,影子模型攻同样适用于生成模型。生成模型多被用于在无监督学习下生成与训练数据分布尽可能相近的数据。Hayes等人 (Hayes et al., 2019) 提出了第一个针对生成模型的成员推理攻击,其原理是生成对抗网络(GAN)的判别器(discriminator)被训练来学习训练数据与生成数据之间的统计差异,因此会以更高置信度输出训练数据(即“成员”)而以相对降低的置信度输出生成数据(即“非成员”)。作者分别研究了白盒威胁模型和黑盒威胁模型下的攻击方法。在白盒威胁模型下,攻击者对目标模型具有完全访问权限,故可以先将所有目标数据(要攻击的样本)输入目标鉴别器,以得到能够反映对应样本属于原始训练数据的置信度。对鉴别器的输出概率向量进行降序排序,排序靠前的数据则极有可能为“成员”。值得注意的是,在白盒模型下,此攻击并不需要训练影子模型,因为鉴别器所提供的的信息已足够。而在黑盒威胁模型下,攻击者仍然需要训练影子生成模型,并使其模仿目标生成模型的表现。其中,影子生成模型的训练数据靠目标模型生成器(generator)来生成。影子生成模型训练完毕后,剩余攻击步骤与白盒威胁模型类似。此外,Hayes等人 (Hayes et al., 2019) 将要攻击的目标数据限定为与训练数据(欧式距离)相近的数据,因为当目标数据为训练数据或生成数据时才能达到较高攻击准确率。而Liu等人 (Liu et al., 2019) 则不在目标数据上做限制,他们同样在黑盒威胁模型下构建影子生成模型,但是利用影子鉴别器(shadow discriminator)来进行攻击。
4.2.1.2. 指标指导攻击¶
与影子模型攻击不同,指标指导的成员推理攻击(metric-guided membership inference attack)通过预先指定的统计指标来检测“成员”样本,跟异常检测(anomaly detection)类似。 其中,成员检测指标大都根据目标模型的概率输出计算得到,然后将指标与预设的阈值做比较,以此作为判断某样本是否为成员的依据。已有成员检测指标大致可分为四类:预测正确性(prediction correctness)、预测损失(prediction loss)、预测置信度(prediction confidence)和预测熵(prediction entropy)。我们将攻击定义为推理函数\({\mathcal{M}}(\cdot)\),其输出\(1\)或\(0\)分别代表“成员”和“非成员”。
预测正确性。 一种最简单的攻击方式就是认为“只要预测成功了就是成员样本”,这里假设模型无法向测试集泛化,所有预测成功的都是训练样本。对应的判定函数为:
其中,\({p}_i({x})\)为模型输出概率响亮的第\(i\)维(对应第\(i\)个类别),\(\mathbb{1}[\cdot]\)为指示器函数(indicator function)。 这种推理攻击的攻击效果跟目标模型的基本性能相关,在某些很少见的情况下效果其实并不差,比如测试准确率很低的困难问题或者问题本身不难但是测试集里包含很难的样本等。这里举个简单的例子,使用机器学习模型预测股票价格,如果能连续预测正确则大概率是训练过的数据。 但是对于相对简单的任务,目标模型本身就具有不错的泛化性能,那么这种攻击方式将会失效,只能大概率确定分不对的样本是“非成员”而无法说明分对的样本就是“成员”。
预测损失。 Yeom等人 (Yeom et al., 2018) 在其工作中建立了成员推理攻击、属性推理攻击以及过拟合之间的理论关联,并提出借助模型在训练数据和测试数据上的平均损失大小差异进行成员推理攻击。此攻击思想对应机器学习训练与测试数据点之间的分布偏差(由采样引起)。 Yeom等人将成员判定阈值设为所有训练样本的平均损失,对应的推理函数如下:
其中,\(\mathcal{L}( \cdot, \cdot )\)为损失函数(如交叉熵损失),\(\tau\)为所有训练样本的平均损失。
预测置信度。 Salem等人在其工作 (Salem et al., 2019) 中除了提出放松假设的白盒影子模型攻击外,还提出了基于预测置信度以及预测熵的指标指导攻击。这里,高预测置信度指的是在预测向量中,其中一个维度的概率远大于其他概率。目标模型的训练会让训练样本的最大概率无限接近于1,因此可以用最大置信度作为指标来检测“成员”样本。推理函数可定义如下:
其中,\(\tau\)为一个预设的接近1的阈值。
预测熵。 Salem等人 (Salem et al., 2019) 还提出了以预测熵为指标的成员推理攻击。 模型输出概率向量的熵衡量了模型在不同类别上的确信程度,低熵说明模型确信的指向某个类别,高熵说明模型在不同类别上犹豫不决。基于预测熵的推理函数可定义为:
Song和Mittal (Song and Mittal, 2021) 认为预测熵应该和样本标签结合起来使用,并提出修正预测熵(modified prediction entropy)来提高上述基于标准预测熵的推理攻击。举例来说,如果目标模型以极高置信度错误分类某个样本,则它的预测熵将无限接近 :math:`0``{=latex},会被攻击者检测为“成员”,而实际上可能是目标模型无法分类的“非成员”样本。考虑了此问题的修正预测熵定义如下:
其中,\(i \neq y\)在概率向量中排除了样本\({x}\)本身的类别\(y\)。将式[equ:chap4metricEntro]中的预测熵替换为修正预测熵便得到基于修正预测熵的推理函数。
4.2.1.3. 联邦推理攻击¶
近年来,联邦学习(FL)打开了多方协作训练的新范式,参与方在不共享数据只共享梯度(或参数)的情况下,综合各方优势共同训练一个强大的全局模型。 前面介绍的成员推理攻击都是在传统集中式学习范式下的攻击,然而联邦学习的多方协作难免会泄露一些特殊的隐私信息,因为毕竟信息(虽然不是数据本身)还是从参与者汇聚到了全局模型。
Melis等人 (Melis et al., 2019) 提出了第一个针对联邦学习的成员推理攻击。此工作以文本分类为例,目标模型是一个包含词嵌入(word embedding)层的递归神经网络。词嵌入层通过一个嵌入矩阵(embedding matrix)将输入投影为低维向量表达,而这个嵌入矩阵会被视作模型的全局变量,在联邦学习的各方共同参与下进行优化。 词嵌入层的梯度是稀疏且与输入词有对应关系的。也就是说,对一批输入文本来说,词嵌入只会根据文本中存在的词进行更新,而其余词(文本中不存在的词)的梯度则为零。攻击者可以利用词嵌入更新的这种特性,通过观察非零梯度来推断一个文本样本是否为“成员”。
Truex等人 (Truex et al., 2019) 则提出了一种针对异构联邦学习的成员推理攻击。在异构联邦学习框架下,参与者利用本地私有数据来训练本地模型,在新样本到来时,参与者与他参与方共享本地模型对新样本的预测向量。异构联邦学习的特点是各方数据不互通且重叠度(overlap)较小,因而不同本地模型之间的决策边界差异很大。 对联邦中的恶意参与者来说,这种决策边界差异就可以用来推理某样本是否存在与其他参与方的私有数据中。
4.2.2. 属性推理攻击¶
属性推理攻击(attribute inference attack,AIA)来源于模型逆向攻击(model inversion attack),是针对个体属性的隐私攻击。攻击者基于已发布的目标模型,从给定样本的非敏感属性中推断其敏感属性。 最初,Fredrikson等人 (Fredrikson et al., 2014) 在2014年通过逆向药物剂量预测模型来推断关于患者的敏感属性。他们根据目标模型输出的华法林预测剂量和患者的非敏感属性(如身高、年龄、体重等)推理得到该患者的基因组信息。具体的,作者将这种攻击形式化为最大化敏感属性的后验概率估计(posteriori probability estimate)。攻击者假设每个患者(数据样本)的特征向量中的某个特征为敏感属性,而其他特征为非敏感属性。给定非敏感属性和模型输出,攻击者通过后验概率最大化(maximum a posteriori,MAP)来最大化敏感属性的后验概率。
上述工作研究的目标模型为简单的线性回归模型(linear regression),在后续的研究中,Fredrikson等人 (Fredrikson et al., 2015) 又将目光投向了深度学习模型。 给定人名,攻击者利用目标模型的输出(预测概率向量)来攻击基于深度神经网络的人脸识别模型,推理出该人物的人脸敏感特征。在这个工作中,Fredrikson等人将属性推理攻击转化为一个优化问题:找出一个输入人脸图像,其能让目标模型以最大概率预测给定人名。 需要注意的是,虽然通过此攻击可以得到一个能迷惑神经网络的(合成)人脸图像,但是这个图像并不属于目标模型的训练数据集,而更像是一个特征聚合的结果。
在Pan等人 (Pan et al., 2020) 的工作中,研究者将个体属性推理攻击扩展到自然语言处理模型。通用语言模型(如谷歌的BERT,OpenAI的GPT-3)将文本转化为嵌入向量,在自然语言处理中起到了至关重要的作用。然而,Pan等人发现攻击者可以训练一个攻击模型,在只知道通用语言模型输出向量的情况下(对原文本一无所知)找到原文本的关键词(也就是敏感属性)。 举例来说,现在很多医疗机构都在构建全自动预诊断机制,以此来提高患者的就诊效率,其中往往会使用通用语言模型来生成病历的词嵌入向量。攻击者在得到这些嵌入向量之后,便可以推理患者的疾病类型甚至是病灶,泄露病人的隐私。
另外,属性推理攻击在图神经网络(graph neural network,GNN)中也具有一定的威胁性。2021年,He等人 (He et al., 2021) 最先提出针对边的推理攻击。他们在黑盒威胁模型下对图神经网络进行攻击,推理两个节点之间是否存在边。推理的大致思想是,图神经网络通过聚合邻居节点信息来计算该节点的嵌入向量,那么嵌入向量距离近的节点间大概率会存在连接。实际上,Duddu等人 (Duddu et al., 2020) 在2020年就系统研究了三种对图神经网络的攻击:1)成员推理攻击,攻击者利用图嵌入(白盒攻击)或者模型输出(黑盒攻击)推理某个用户节点是否存在于目标模型的训练数据集中;2)图重构和边推理攻击,通过图嵌入和自动编码器逆向图的结构信息(邻接矩阵),并基于此推理攻击节点间的连接情况;3)属性推理攻击,攻击者推理有关用户敏感信息的节点属性。作者假设攻击者拥有从同一数据池采样的(但与目标数据不相交)图,这样就可以利用影子模型(章节`5.2.1.1 <#sec:shadow_model_attack>__)来进行攻击。虽然这几种推理攻击的成功率方差很大,很多时候成功率也不高,但是这些工作揭示了图神经网络切实存在的隐私泄露风险,是很重要的一个开始。
4.2.3. 其他推理攻击¶
以智能手机、智能音箱、智能冰箱等为代表的智能家居设备、物联网(Internet of things,IoT)都是隐私攻击的重点对象。例如,无处不在的麦克风可能随时都在“监听”用户的一举一动,说话者的声音、音量及表达方式都有可能暴露他/她们的姓名、性别、年龄、位置、健康状况、醉酒程度、疲劳情况等个人隐私信息。早在2014年,Bone等人 (Bone et al., 2014) 便利用语言错误(如难以理解的单词数量、中断、犹豫等特征)和节奏特征来推断说话人是否醉酒。2015年,Schuller等人 (Schuller et al., 2015) 通过综合调研,分析说明语速、音量、表达特征等语音数据可以被用来推断人格特征。2017年,Cummins等人 (Cummins et al., 2017) 利用声音沙哑程度及咳嗽、吸鼻子的频率来判断说话人是否感冒或喉咙痛。2018年,Jin和Wang (Jin and Wang, 2018)利用音量、音调变化来识别说话人的情绪,包括愤怒、同情、厌恶、快乐、惊讶等。
虽然单个样本所包含的信息有限,但当数百万条样本汇集起来,攻击者就可以从中分析得到很多重要的知识。因此,具有上百万甚至千万用户的在线社交网络平台(以及未来的元宇宙)都可能会成为个人信息泄露的主要场所。社交网络中的用户档案、交互记录、帖子内容等公开数据可能会被用来推断用户的性别、种族、年龄、位置信息、经济状况、政治兴趣等等。 近来,国外已经出现了专门针对社交网络的个人隐私攻击,一些非法公司通过分析社交网络获取用户不愿透漏的隐私信息,并将这些信息打包出售获得高利。 除社交网络外,开放数据集也有可能泄露个人隐私。随着人工智能的快速发展,大规模数据集的构建和开源越来越频繁,政府、公司、组织间共享数据、整合数据优势的行为也越来越普遍,给隐私攻击留下大量的探索空间。
4.3. 数据窃取¶
数据窃取攻击(data stealing attack)从已训练模型中逆向得到模型的原始训练数据,所以也称为数据抽取攻击(data extraction attack)或模型逆向攻击(model inversion attack)。图4.3.1 展示了数据窃取攻击的目的,通常情况下我们利用训练好的模型进行正常推理任务,但是数据窃取攻击者会尝试从模型中逆向出原始训练数据。当前数据窃取攻击针对的主要是深度学习模型研究,利用的是模型在训练过程中记忆的训练数据。数据窃取攻击所带来的威胁是多方面的,会导致私有数据的泄露、知识产权的侵犯等,比上一章节介绍的隐私攻击威胁更大。对数据持有者来说,他们通常花费巨大的代价来收集和标注私有数据,一旦泄露则会导致财产损失,严重时甚至会威胁国家安全。此外,数据的泄露也会破坏保密协定,而当被泄露的数据被用作其他非法目的时,更是会带来一系列附加危害。
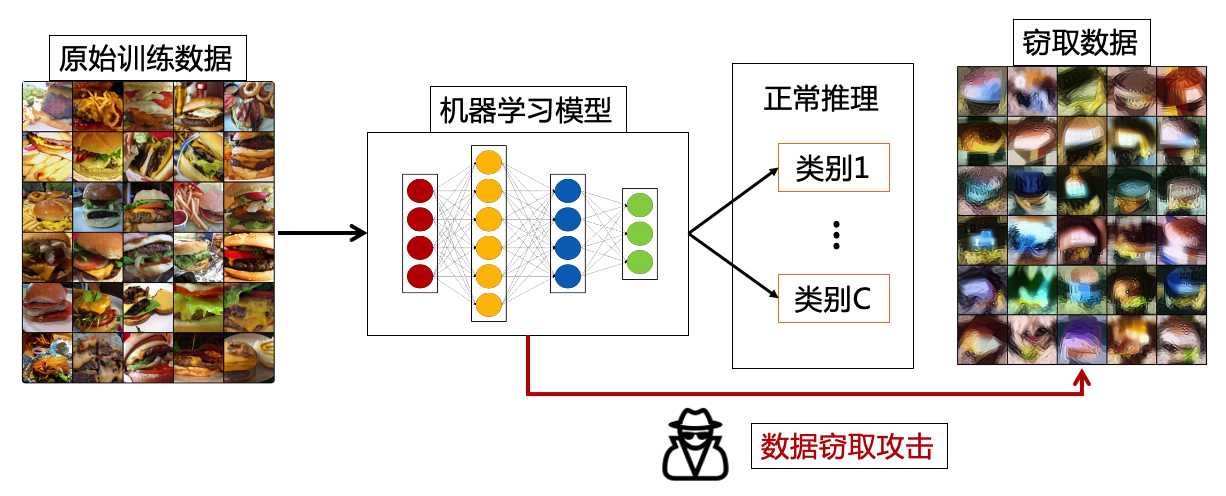
图4.3.1 数据窃取攻击示意图¶
2015年,Ateniese等人 (Ateniese et al., 2015) 指出,如果攻击者可以访问比他们自己的模型表现更好的机器学习模型(如支持向量机、隐马尔科夫模型、神经网络等),那么就可以通过对目标模型的访问来推理有关训练数据的信息,进而用于改进自己的模型。在这项工作中,Ateniese等人关注的是能帮助攻击者提高自己模型性能的信息,而不是原始训练数据的泄露。
以此为启发,Song等人 (Song et al., 2017) 首次提出了模型记忆攻击(model memorization attack)的概念,通过(伪)正则化或者数据增强技术将训练数据记忆在深度神经网络里,从而可以在后续的步骤中以白盒或者黑盒的方式访问目标模型提取记忆的数据。 该工作假定攻击者为恶意服务提供商,在机器学习即服务(machine learning as a service,MLaaS)的设定下,在向用户提供训练数据增强技术、模型架构及训练代码等服务的同时将训练数据藏在模型参数中进行窃取。在白盒威胁模型下,攻击者可以访问目标模型参数,提取参数中记忆的训练数据。在这种情形下,攻击者可以直接修改训练算法代码,采用编码(encoding)技术将数据藏在模型最不明显的比特(least significant bits,LSB)中,亦或使用正则化技术将敏感数据与模型参数(或者参数的正负号)建立关联和记忆。在黑盒威胁模型下,攻击者只有模型的使用权(即输入输出访问权),所以可以使用预埋的恶意数据增广技术,在增广得到的新样本(称为恶意增广样本)的类别标签里隐藏原始训练数据的信息,一个恶意增广样本负责一个比特,从而在推理阶段可以通过恶意增广样本逐一提取这些比特,组合成泄露数据。此类攻击需要很强的假设,即攻击者能够自由执行修改后的训练算法和数据增广技术,而且能窃取的数据量相对较小,比如最核心的敏感信息。
上述攻击是一种恶意的“有意”记忆导致的信息泄露。相比“有意”记忆,更令人担忧的是深度学习模型”无意“或”意外”的记忆。Carlin等人 (Carlini et al., 2019) 将意外记忆(unintended memorization)定义为训练有素的神经网络所暴露的分布外(out-of-distribution)训练数据,这些分布外训练数据与学习任务无关却被神经网络(意外地)记住了。
数据窃取攻击与上一章节介绍的属性推理攻击有什么不同? 首先,数据窃取攻击与属性推理攻击都是重构还原(全部或者部分)训练数据的过程。区别在于,属性推理攻击的目标是得到使目标模型以最大概率输出特定类别的数据,这意味着其学习的是训练数据的聚合统计属性。如在攻击人脸识别模型的工作 (Fredrikson et al., 2015) 中,攻击者最终得到的是合成人脸图片(被目标模型预测为预定类别)而非实际训练数据。而对于数据窃取攻击来说,它的目的是最大程度的还原训练数据。虽然属性推理攻击也在一定程度上泄露隐私信息,但是其所涉及的对象往往是单个隐私属性,而数据窃取往往泄露的是整个数据集,所造成的危害更大、影响范围更广。当然数据窃取攻击也比属性推理攻击更难实现。
根据攻击者所掌握的信息,数据窃取也可分为黑盒窃取和白盒窃取。概括来说,在黑盒威胁模型下,攻击者只可以与目标模型交互,得到攻击者给定输入的对应输出;而在白盒威胁模型下,攻击者可以访问目标模型的内部结构和模型参数。下面将从黑盒与白盒两个类别进一步介绍数据窃取攻击方法。
4.3.1. 黑盒数据窃取¶
在黑盒数据窃取设定下,攻击者所掌握的信息并不多,只有模型的输出结果,所以只能攻击特定类型的模型,且只能窃取部分数据信息。一般来说,模型的输出维度越高就越容易受到黑盒数据窃取,比如生成模型、序列到序列模型等,这主要是因为输出维度越高暴漏的信息也就会越多。相反的,如果是对输入信息压缩很厉害的分类模型,则难以仅根据输出概率去窃取输入信息。此外,黑盒窃取能获得的信息也非常有限,目前的攻击只能获得与输入样本相关的一些信息。
现有黑盒数据窃取攻击主要针对大语言模型(large language models)——为单词序列分配概率的统计模型。这类(开放的)语言模型是许多自然语言处理任务的基础,其往往使用非常大的模型架构,并在海量文本数据上进行训练。这种大规模学习的方式赋予了语言模型生成通畅自然语言的能力,被广泛应用于各种下游任务。训练大语言模型的数据集往往包含大量公开在互联网上的文本数据,这些数据经常(意外地)包含个人隐私信息(如身份证号码、手机号码、邮箱、家庭住址等),在面临窃取攻击时容易发生关联泄露(比如出现人名的时候也往往连带着电话号码或家庭住址)。
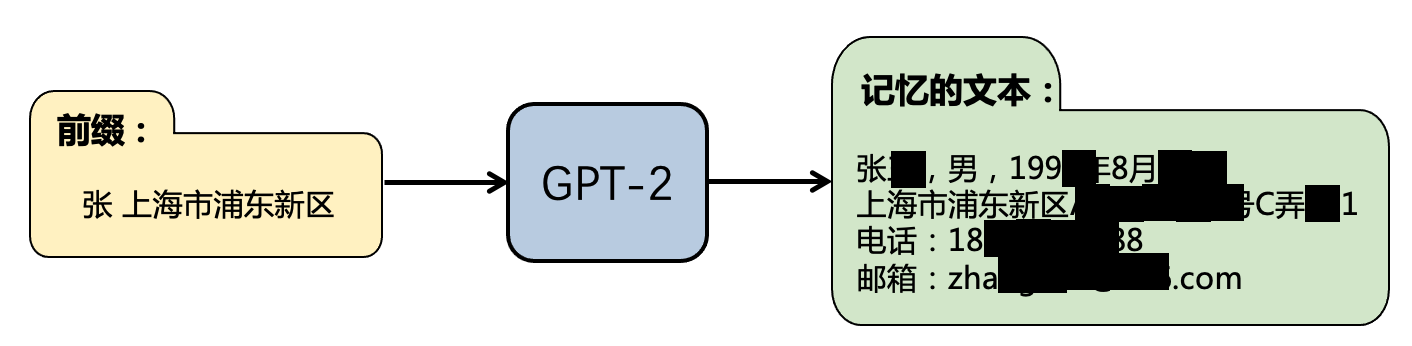
图4.3.2 黑盒数据窃取示意图¶
图4.3.2 展示了一个黑盒数据窃取攻击自然语言处理模型的例子,当输入特定前缀文字后,语言模型自动返回了模型记忆的与前缀文字关联的其他隐私信息。这是由Carlin等人 (Carlini et al., 2019) 发现的模型的意外记忆。神经网络的设计本意是专注于学习与任务高度相关的数据而忽略任务无关的信息,然而Carlin等人的工作证明了意外记忆的存在和敏感信息泄露的可能性。
为了以一种可控的方式研究并量化模型的记忆,Carlin等人手动构建了与目标学习任务无关的“先兆数据”(canaries[^9])。通过定义并计算这些先兆数据在语言模型中的“曝光度”(exposure)可以定量的考核模型是否存在意外记忆以及记忆程度。先兆数据是从输入域中抽取的独立随机序列,随后以不同次数注入训练数据中。举例来说,给定一个格式“我的社会保障号码为\(\ast \ast \ast \ast \ast \ast \ast \ast \ast\)”(美国社会保障号码长度)和数据域\(0-9\),每一个\(\ast\)都是从数据域\(0-9\)中随机选取的,一个简单的例子为“我的社会保障号码为281265017”。实验同时需要设计对照数据,如与先兆数据只相差一位数的“我的社会保障号码为281265018”。Carlin等人将先兆数据注入一个神经网络机器翻译(neural machine translation,NMT)模型中发现,有时候先兆数据只需注入一次就会让模型记住它,导致信息被推理出的概率大大升高。
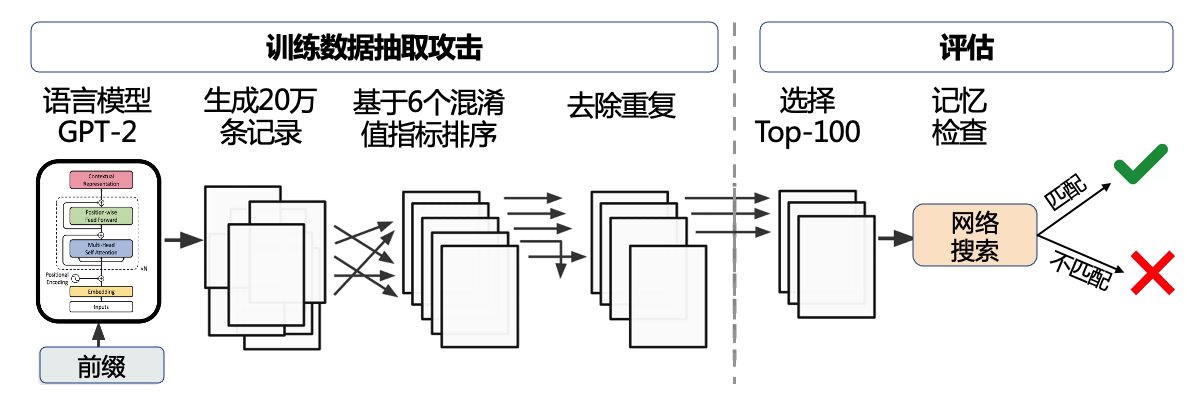
图4.3.3 黑盒数据窃取流程图¶
在的后续工作中,Carlini等人 (Carlini et al., 2021) 将数据窃取的设定进行了一定的泛化。之前的工作假定攻击者知道他们想要“窃取”的目标数据(如社会保障号码),是一种定向攻击。在新的工作中,他们假设攻击者的攻击目的是尽可能多地从模型中窃取训练数据,是一种普适攻击。 在普适攻击设定下,攻击者可以使用成员推理攻击来辅助黑盒数据窃取。 此攻击改进了文本的生成方式,使生成的文本更多样化,同时以混淆值(perplexity)作为成员推理的基准指标,并结合超参数调整和额外互联网数据(与GPT-2类似的前缀数据),力求从模型中生成出更多样化的样本。混淆值的定义如下:
其中,\(f_\theta\)为目标语言模型,是概率生成模型的一种。对一个序列\(\{{x}_1,\cdots,{x}_i\}\)计算混淆值,混淆值高表示目标模型对给定序列的出现是“惊讶的”,而混淆值低意味着给定序列对目标模型来说是一个普通的(意料之中的)序列。
如 图4.3.3 所示,研究者在大语言模型GPT-2及其变体上进行了实验验证。给定一个模型,先生成20万条文本,然后通过6个混淆值指标对文本进行排序(各自独立排序),去除重复并(以网上搜索确认的方式)人工检查前100条记录。最终,通过与数据拥有方OpenAI进行确认,研究者成功逆向了604条训练文本,其中包括100条新闻报道、79条日志或者错误报告记录、32条私人通讯信息(如地址、电话、邮箱和Twitter账户)等。更让人担忧的是,即使包含上述信息的文档在训练数据中只出现一次,攻击也能有可能成功。
4.3.2. 白盒窃取¶
白盒窃取攻击对目标模型具有完全访问权限,可以获得模型结构和参数,并基于此从目标模型中窃取训练数据。在这种情况下,攻击者往往利用梯度信息进行数据窃取,因此此类攻击也被称为梯度逆向攻击(gradient inversion attack)。 由于联邦学习在设计上需要各方共享模型参数或梯度信息,这使其更容易遭受白盒数据窃取攻击。实际上,白盒数据窃取攻击也大都以联邦学习范式为主要攻击目标。根据优化目标的不同,梯度逆向攻击可以分为两类:迭代梯度逆向(iterative gradient inversion)和递归梯度逆向(recursive gradient inversion)。迭代梯度逆向攻击通过迭代来步步缩小生成梯度与真实梯度(各方共享梯度)之间的差异;而递归梯度逆向攻击则对神经网络从后往前逐层递归优化,得到每层的最优输入。
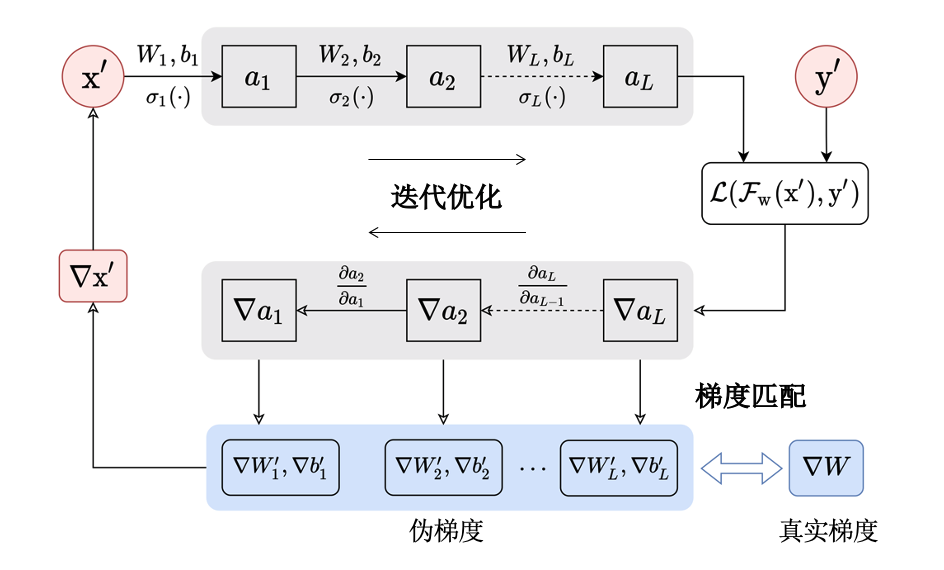
图4.3.4 迭代梯度逆向攻击流程图¶
迭代梯度逆向攻击的思想是通过生成。 一种经典的迭代梯度逆向攻击方法是Zhu等人 (Zhu et al., 2019) 提出的深度梯度泄露(deep leakage from gradients,DLG)攻击。如:numref:fig_chap4iterativeGradientInversionAttack 所示,迭代梯度逆向攻击主要包括三个部分:伪数据初始化、梯度求导和梯度匹配。攻击者首先初始化一个随机样本\({x}'\)和随机标签\(y'\),然后通过对伪数据\({x}'\)进行优化来还原初始训练数据。具体的,将\({x}'\)输入模型,经过正向及反向传播得到模型每一层参数的伪梯度\(\{\nabla \theta'_i=(\nabla W'_i, \nabla b'_i)\}_{i=1}^{L}\)(\(L\)为神经网络层数)。然后,迭代最小化伪梯度\(\nabla \theta'_i\)与真实梯度\(\nabla \theta_i=(\nabla W_i, \nabla b_i)\)之间的距离,使生成数据趋近目标模型的训练数据。将上述步骤迭代数次并收敛后即可得到无限近似原始训练数据的合成数据,优化过程定义如下:
其中,\(\parallel{ \cdot}\parallel_2\)表示\(L_2\)范数,\({x}^{*}\)、\(y^{*}\)分别表示优化得到的窃取样本和标签。 大部分伪数据的初始化选用高斯噪声 (Yin et al., 2021, Zhu et al., 2019),也有部分工作 (Jin et al., 2021, Zhao et al., 2020) 选择均匀分布噪音。在迭代梯度逆向的过程中,伪样本和伪标签会在模型训练过程中一起迭代升级。但Zhao等人 (Zhao et al., 2020) 发现,深度梯度泄露攻击无法保证同时完成模型收敛和正确标签窃取两个任务,因此对深度梯度泄露攻击提出了改进,预先从真实梯度中窃取正确标签,然后只对伪样本进行优化。这一做法有效降低了计算复杂度,提高了窃取效率。
对普通模型训练来说,基于批的训练有助于减少迭代次数,减缓累积误差造成的波动。但是对于数据窃取来说,基于批的训练会造成梯度混杂,给窃取增加了难度。实际上,从混杂梯度中提取梯度和目标数据等同于做平均和分解(decomposition of averaged summation)。深度梯度泄露攻击使用的普通优化策略可以计算批大小最大为8的混杂梯度。而Jin等人 (Jin et al., 2021) 借助正则化项,成功的从批大小为100的混杂梯度中窃取到了数据。此外,如公式 [equ:chap4dlg] 所示,深度梯度泄露攻击在计算伪梯度与真实梯度之间的距离时使用了\(L_2\)范数。然而,Geiping等人 (Geiping et al., 2020) 研究发现,对数据窃取攻击来说,梯度的方向比大小更重要,进而使用余弦相似度(cosine similarity)来代替 \(L_2\) 距离,取得了更好的窃取效果。
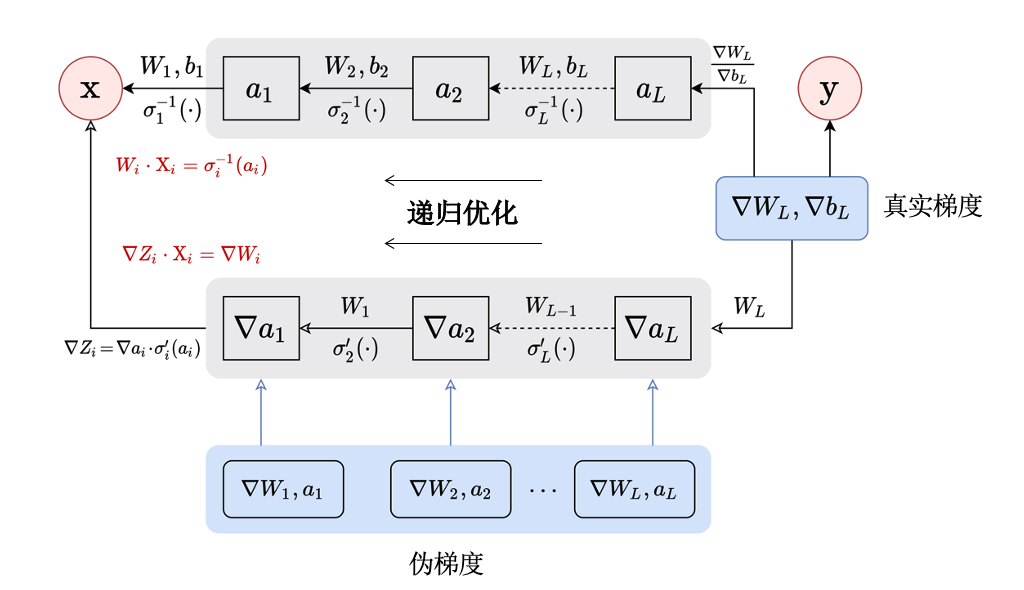
图4.3.5 递归梯度逆向攻击流程图¶
递归梯度逆向攻击的思想是通过真实梯度来反向推断神经网络每一层的输入,一直到输入层。最简单的情况是每一层都是一个感知器(perceptron)。Phong等人 (Aono et al., 2017) 发现当损失是均方差损失函数时,感知器的某一维的输入可以直接通过当前感知器的梯度逆向得到:
其中,\({x}^{(k)}\)和\(W^{(k)}\)是输入和模型参数的第\(k = 1,\ldots,d\)维,\(b\)为偏置变量。 而这个结论也被进一步扩展至全连接层(fully connected layer)和多层感知器(multilayer perceptron,MLP)。只要偏置项存在,那么就可以通过梯度来逆向推导多层感知器的输入。随后,Zhu和Blaschko (Zhu and Blaschko, 2021) 将这个结论进一步泛化至卷积层(convolutional layer)。为了成功窃取第一层卷积的输入,也就是训练数据,Zhu和Blaschko将迭代梯度逆向攻击表述为求解线性方程组的过程:
其中,\({z}^{(i)}\)、\(\nabla {z}^{(i)}\)表示输入数据的特征及其对应梯度(损失\(\mathcal{L}\)对于\({z}^{(i)}\)的梯度),\(a\)、\(\sigma( \cdot )\)分别表示神经元的输出和每层神经网络的激活函数。从理论上来说,从最后一层全连接开始递归计算,是可以逐像素还原原始输入数据的。需要注意的是,递归梯度逆向攻击目前只被证实能作用于卷积层和全连接层,而无法应用在池化层(pooling layer)和跳跃连接(skip connection)。此外,递归梯度逆向攻击也不能很好地还原批次数据。
4.4. 篡改与伪造¶
篡改和伪造主要是指利用深度伪造(deepfake)等多种技术对图像和视频进行篡改。根据被篡改数据的内容和类型,又可分为普通篡改和人脸伪造。下图以AI换脸为例,展示了利用深度伪造技术对图像进行篡改的一般流程。深度伪造技术可以轻松地对图像进行编辑和修改,生成具有误导性或欺骗性的内容,被恶意篡改的内容在经过传播后,会造成误导舆论、扰乱秩序、损坏名誉、骗取钱财等恶性事件的发生。与其他技术不同,现在有很多工具都提供了深度伪造的功能,这些工具能够很轻易为普通人所用,使得伪造多媒体能够被低成本、大规模地制造。这由此也促进了针对篡改和深度伪造等的检测技术的发展。本章将围绕篡改和伪造技术进行介绍,篡改与深度伪造检测技术将在章节6.4中介绍。
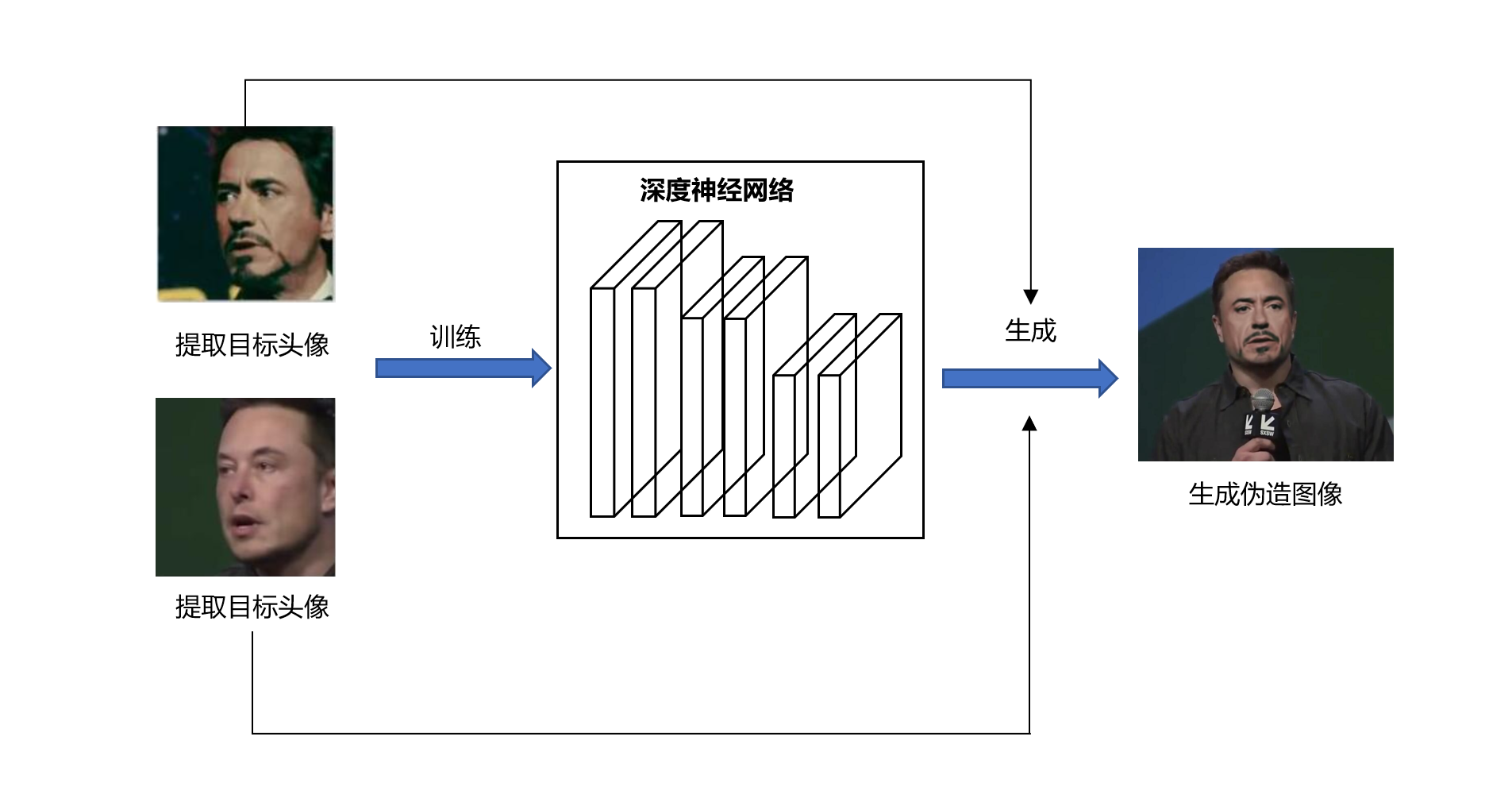
图4.4.1 利用深度伪造技术进行AI换脸流程图¶
4.4.1. 普通篡改¶
普通篡改一般涉及移动图像中视觉元素的空间位置、抹掉原有内容并修复出新伪造内容等修改原始图像的行为。最简单的图像篡改技术可以是各种修图工具,可以对少量图像进行手动修改。实际上,图像理解、编辑和修改是计算机视觉和图形学领域的经典研究问题,在近几十年的发展过程中提出了大量的方法。后来在深度学习模型的推动下,出现了大量交互式的、智能的图像编辑工具,如风格修改、颜色刷、纹理变换、图像修复等等。这些方法让高效的、大批量的图像篡改成为可能。
在基于深度学习的方法中,针对图像的篡改有多种建模方式,首先,图像中的物体、背景等元素之间存在语义关联,传统的基于深度学习的篡改方法有基于上下文的图像修复( (Pathak et al., 2016) )、基于条件的生成模型( (Wang et al., 2018) )等。这些方法解决的核心问题是如何对图像中的不同元素进行解耦,如物体的背景和前景、纹理和结构等,其中主要关注的是是物体的前景、也即物体本身。在解耦后需要对图像中的不同元素进行建模,图片中物体的形状、物体与物体之间的互动和相对位置都可以进行建模。随着技术的发展,建模的粒度逐渐由粗到细,如Hong等人 (Hong et al., 2018) 提出对场景图构建物体级别的语义分割图,这是一个从粗粒度到细粒度逐级进行的分级语义修改框架。用户可以借助一个结构生成器和一个图像生成器通过操控语义对象来篡改图像。它首先以粗略级别的边界框初始化图像生成器;然后通过创建像素级的语义布局(semantic layout),捕捉物体的形状、物体与物体之间的互动以及物体与场景的关系;最后,图像生成器在在语义布局的指导下填充像素级纹理。这样的框架允许用户通过添加、移除或移动边界框,在物体层面上操作图像,展现出了比之前的方法更好的效果。如:numref:fig_chap4semanticManipulation 所示为该分级语义修改框架的架构。

图4.4.2 分级语义修改框架¶
除了对前景物体进行修改,也可以对图像背景进行修改与替换。与前景物体相比,通过将背景视作图像中更大一些的一种物体,如天空、草地、建筑物、室内场景等,以此对其进行建模。以将图片中的天空作为背景为例,Zou等人 (Zou et al., 2022) 提出了天空置换算法,以解决拍摄户外照片时出现的天空过曝、景色不佳的状况。所提出的算法由三个核心部分组成:第一部分是由卷积神经网络实现的天空分割网络,用以根据图像生成像素级模板,进而区分画面中的天空和非天空区域,以去掉需要置换的天空像素;第二部分是运动估计模块,它假定天空在无限远处,使用两个相邻的实现的天空置换算法能够用于视频中的天空置换,自动生成逼真的天空背景,更改视频画面中的天气。该工作模型及算法由三个核心部分组成:第一部分是天空抠图网络,主要是一个卷积神经网络,根据图像生成一个像素级模板,用于区分画面中的天空与地面,去掉需要置换的天空像素;第二部分是运动估计,假定天空在无限远处,使用两个相邻的画面帧计算出天空相对于画面的偏移量;第三部分是图像融合,首先进行天空色彩风格的迁移,然后将新的天空图像作为一个360度的背景,根据第二部分计算出的偏移来确定前景在新的天空中的位置,并实现天空的置换。另一个方法Image2GIF (Zhou et al., 2018) 甚至训练了一个能够在给定单一图像的情况下自动生成电影片段序列的计算模型。他们将生成模型、递归神经网络及深度网络相结合,以增强序列生成的能力。
随着文本-图像预训练模型的兴起,现在一个新的图像篡改方向是:通过文本命令实现对要被篡改的图像的操控。由Kim等人 (Kim et al., 2022) 提出的对比语言-图像预训练模型(contrastive language-image pretraining,CLIP) (Radford et al., 2021) 和扩散模型(diffusion (Ho et al., 2020, Song et al., 2021) 是这个领域方法的代表。CLIP和扩散模型完成了在零样本(模型并未在类似的图像上训练过)下对图像中通用物体和属性的修改,如建筑物风格、天气场景、发型装饰等。CLIP模型通过搜集大量的文本-图像配对数据进行训练,很好的解决了常规的图像分类模型在进行全监督训练时对数据要求高、需要大量人工标注的缺点,提高了模型的泛化能力和适用性。而在扩散模型流行之前,文本指导的图像篡改大都通过生成对抗网络来完成,如TediGAN (Xia et al., 2021) 、StyleCLIP (Patashnik et al., 2021) 和StyleGAN-NADA (Gal et al., 2022) 等方法。总体来说,由于缺乏对特定领域数据的学习,这些借助CLIP预训模型的文本指导图像篡改方法往往精细化程度不够,大都会留下明显的痕迹。但是这些方法的潜在危害不容忽视,它们在方便图像编辑的同时也大大降低了图像篡改的门槛,且未来可能会与其他大规模预训模型(如物体分割模型)结合,达到更精准、更细粒度的图像篡改。
4.4.2. 深度伪造¶
深度伪造特指基于深度学习技术生成的伪造数据。在深度学习技术广为流行的今天,可以说任何人都可通过深度伪造软件轻松创建图像、视频或语音等伪造内容。当前,深度伪造最广泛使用的深度学习技术是生成对抗网络,预计未来会包括扩散模型。生成对抗网络的设计理念源于博弈论中的“零和博弈”(zero-sum game)思想,其通过一个生成器 (generator)模型和一个判别器(discriminator)模型之间的相互博弈来学习真实数据分布,如图5.13所示。其中,生成器基于随机噪声向量生成数据样本,让判别器无法区别样本的真实性;而判别器则尝试将生成器生成的样本判别为假样本。二者以这种对抗式的方式通过交替优化达到纳什均衡状态,此时生成器能够生成“以假乱真”的数据样本,使判别器无法判别真伪,即判断准确率相当于随机猜测。相比于其他生成模型生成对抗网络具有一定优势: 1)不依赖先验知识; 2)生成器的参数更新来自判别器的反向传播,而非直接来自于数据样本,故训练不需要复杂的马尔可夫链(Markov chain)。生成对抗网络在图像编辑、数据生成、恶意攻击检测、肿瘤识别和注意力预测等领域具有广泛应用,本小节关注的是其在深度伪造方面的应用。
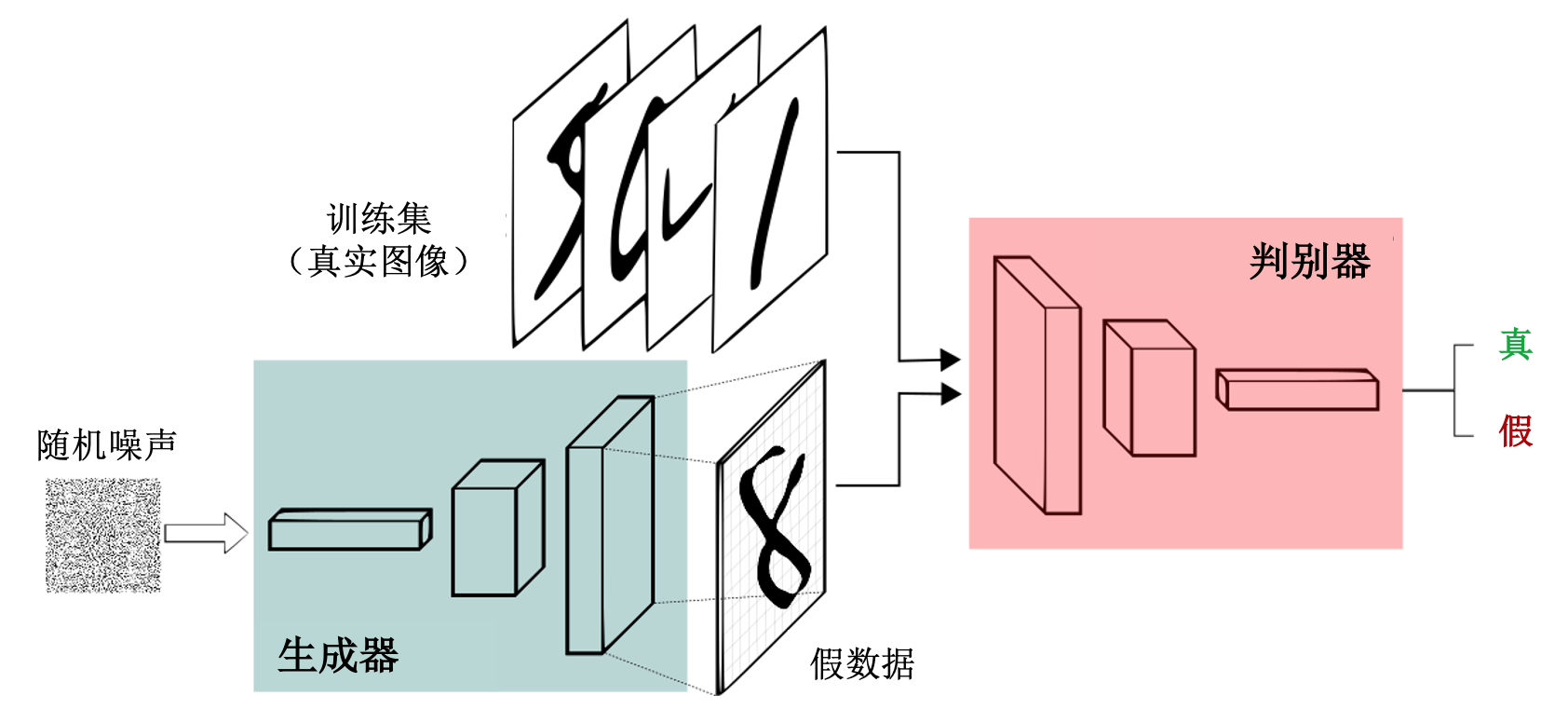
图4.4.3 生成对抗网络¶
4.4.2.1. 人脸伪造¶
2017年,Korshunova等人 (Korshunova et al., 2017) 提出了一种基于生成对抗网络的自动化实时换脸(face swap)技术。同年,Suwajanakorn等人 (Suwajanakorn et al., 2017) 使用长短期记忆网络(long short-term memory,LSTM)设计了一种智能化学习口腔形状和声音之间关联性的方法,该方法仅通过音频即可判断生成对应的口部特征。研究者利用美国前总统奥巴马在互联网上的音视频片段,生成了非常逼真的假视频。此技术一经问世便引起了广泛关注,基于其原理实现的换脸项目也大量出现,极大的刺激了视觉深度伪造技术的发展。
视觉(主要是人脸)深度伪造技术的实现大体可分为数据收集、模型训练和伪造内容生成三个步骤。假设我们的目标是将Alice的脸换至Bob的身体上,可以通过以下的几个步骤进行实现。
4.4.2.1.1. 数据收集¶
数据收集顾名思义就是通过各种渠道对Alice和Bob的已有图像进行大量收集,以便为模型训练提供数据支撑。对于公众人物来说,数据收集可以说是不费吹灰之力,因为他们有大量的演讲、报告、报道等大量的数据公布在网上。注意这里收集的是人脸图像,所以很多时候需要使用人脸检测工具将人脸区域检测并截取出来。
4.4.2.1.2. 模型训练¶
目前,针对人脸伪造的深度伪造模型主要基于自动编解码器,一般由编码器(encoder)和解码器(decoder)两部分构组成。 编码器用于提取人脸图像的潜在特征,解码器则用于重构人脸图像。为了实现换脸操作,模型需要两对编码器/解码器组(编码器A/解码器A、编码器B/解码器B),分别基于已收集的Alice和Bob的图像集进行训练,其中编码器A和编码器B具有相同的编码网络(即参数共享)。通过统一的编码器可以吧Alice和Bob两个人的人脸特征编码到同一个隐式空间,只有在同一个隐式空间,二者的脸部特征才能发生互换。两套编解码器的训练过程如 图4.4.4 (a)所示。
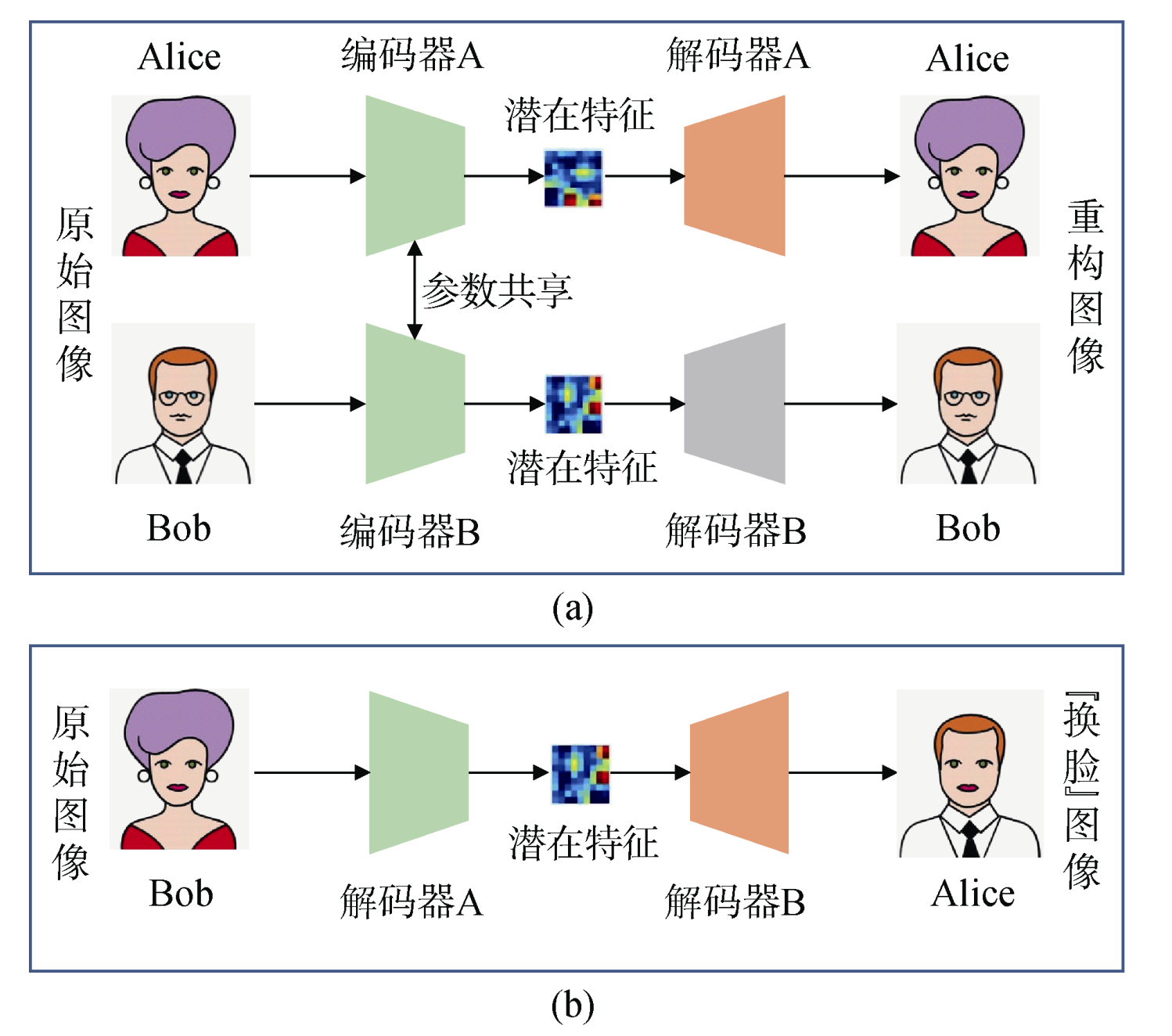
图4.4.4 深度伪造内容生成流程¶
4.4.2.1.3. 伪造图像生成¶
待模型训练完成之后,通过将Alice和Bob的解码器互换,进而构建新的编码器/解码器组(编码器A/解码器B,编码器B/解码器A),然后选取Alice的一张图像作为目标图像,在编码器A编码完成之后,基于解码器B进行解码,从而生成载有Alice面部、Bob身体的深度伪造(换脸)图像,如图 图4.4.4 (b)所示。
人脸伪造技术可以按照对人脸图像的修改程度分为两类:人脸互换和面部重演。总的来说这两类修改目标都可以基于自动编码器来完成,通过解耦人脸的身份与表情信息实现不同维度、不同层次的特征提取,并最终将输入的人脸扭曲后重建出伪造的人脸。通过引入生成对抗网络我们可以大幅提高替换后人脸的真实,即添加一个判别器来判别生成图像和真实图像,强制解码器生成高度真实的换脸图像。
人脸互换的方法有很多种,其目标都是用目标人物的脸替换原图像中的人脸。传统的人脸互换的方法如FaceSwap等通常缺乏泛化性,无法保留面部表情和注视方向等属性、生成人脸图像质量差等问题。为了提高人脸互换的泛化性,Chen等人 (Chen et al., 2020) 提出了SimSwap框架以实现通用且高保真的面部交换。为了将特定身份的人脸互换结构扩展到任意人脸呼唤,SimSwap引入了身份注入模块,在特征层面将源脸的身份信息转换到目标脸。同时,SimSwap提出弱特征匹配损失,得以隐式地、有效地保留面部属性。通过以上的方法,SimSwap能够用任意目标脸替换任意源脸,同时保留目标脸的面部身份特征属性,实现将特定身份的人脸互换结构扩展到任意人脸互换。为了生成更加高质量的人脸图像,FaceShifter (Li et al., 2020) 提出了分别用于脸部交换和遮挡处理的两个网络:AEI-Net和HEAR-Net。具体来说,AEI-Net由三个部分组成:1)身份编码器,采用预先训练好的人脸识别模型,提供抽象身份表征;2)一个多级属性编码器,对面部属性的特征进行分级和编码;3)AAD生成器,将身份和属性信息进行融合并生成伪造的人脸。相应地,HEAR-Net以自监督的方式训练,它可以恢复异常(如遮挡)区域。
相较于人脸互换,面部重演的目标是将源图像中人的面部表情转移到目标人身上,同时保留源图像的身份信息。早在2014年,Garrido等人 (Garrido et al., 2014) 就提出一个自动化的人脸互换和重演框架,其通过人脸追踪(face tracking)、人脸匹配(face matching)以及人脸迁移(face transfer)三个主要步骤,逐步的将用户的人脸迁移到目标视频中。最终,研究者将自己的面部替换到了美国前总统奥巴马的演讲视频中,并完成了奥巴马演讲表情的重演,虽然研究者自己的表情跟演讲并不对应。此工作实现了面部替换和重演的全部自动化,并且只需要用户随意录制一个短视频即可,不需要做跟目标视频中一样的面部表情。
与传统的面部重演不同,Song等人 (Song et al., 2021) 提出了一个新的概念,幻想人脸重演(pareidolia face reenactment),即目标人脸不是常规的人脸,而是卡通、树皮、机器人、姜饼人等“幻想”出来的人脸。这引发了两个新的挑战,即形状差异和纹理差异。在这项工作中,研究者提出了一种新的参数化无监督重现算法来解决这两个挑战。具体来说,研究者将人脸重演分解为三个过程:形状建模、运动转移和纹理合成,并有针对性地引入了三个关键部分,即参数化形状建模、扩展运动转移和无监督纹理合成器,以克服罕见的脸部变异所带来的问题。
表情重演仅是人脸重演的一个部分,还有更多的工作着重于将两张图像上的人脸进行交换,例如FSGAN (Nirkin et al., 2022) 进行的人脸交换工作。首先,互换生成器 \(G_r\)估值源图像的分割掩码。然后,画中画生成器\(G_c\)对缺失部分进行修复并得出完整的交换脸。最后,使用分割掩码及混合发生器\(G_b\)混合上述结果,生成最终的输出。nirkin2019fsgan
此外,为了实现主体无关的面部重演,First-order-motion (Siarohin et al., 2019) 对外观和运动信息进行解耦。他们的框架包括两个主要模块:1)运动估计模块,使用一组学习得到的关键点以及它们的局部仿生变换来预测密集的运动场; 以及,2)图像生成模块,结合从源图像中提取的外观和从驱动视频中得到的运动来模拟目标运动中出现的遮挡。CrossID-GAN (Huang et al., 2020) 将目标人脸的图像输入到人脸编码器提取身份信息,将源人脸图像对应的人脸关键点输入到关键点编码器中提取表情信息,并将两个部分的特征拼接在一起后输入到解码器中进行人脸图像生成。为了保证生成图像和源图像的表情一致,CrossID-GAN提出利用训练好的关键点检测器分别提取二者的关键点并计算 \(L_1\)距离;同时为了保证生成图像和目标图像的身份一致,他们训练一个身份判别器并在其监督生成人脸。PuppeteerGAN (Chen et al., 2020) 将源人脸图像的语义分割图和目标人脸的关键点输入到骨架网络中,学习语义分割图的迁移,并输出源人脸被重演为目标人脸的含表情语义分割图,然后将其与源人脸图像一起输入到染色网络中最终生成同时保留源人脸身份及目标人脸表情的图像。
Sun等人 (Sun et al., 2022) 提出的FENeRF是一个3D感知生成器,它可以生成视图一致并可以在本地编辑的面部图像。FENeRF使用两个解耦的编码在同一个3D空间中,分别生成对应的面部语义信息和纹理。受益于这种底层的3D表达,FENeRF得以渲染出没有裁切边界的图像和语义掩码,并使用语义掩码通过生成对抗网络来编辑3D信息。实验进一步表明,可以从普通单目图像和语义掩码对中学习这种3D表示。实验也表明联合学习语义和纹理有助于生成更精细的图像。
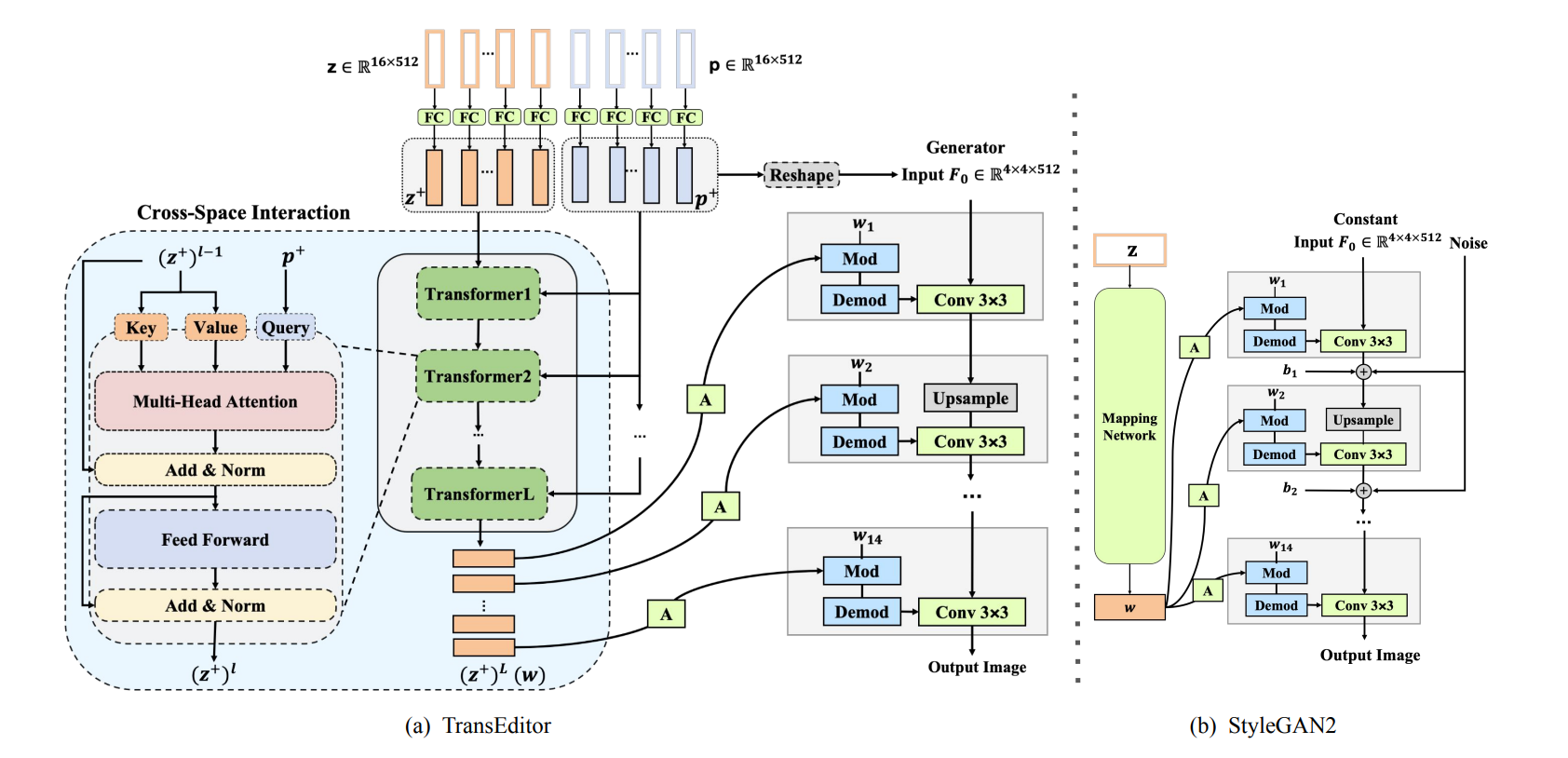
图4.4.5 TransEditor及所采用的StyleGAN2的架构图¶
Xu (Xu et al., 2022) 提出了TransEditor,是一种基于Transformer 的双空间生成对抗网络,可以进行高度可控的面部编辑。通过引入跨空间注意力机制,两个潜在空间进行有意义的交互。此外,该工作利用TransEditor提供的可控性提出了一种灵活的双空间图像编辑策略。实验证明了TransEditor可以进行高度可控和稳定的面部属性编辑,并表现出了非常好的效果。
基于人脸伪造技术,研究者们同时还构建了一系列的人脸篡改数据集,包括了UADFV
(Li et al., 2018) 、DFDC (Dolhansky et al., 2019)
等等。详细的数据集基本信息如下表
`{=latex}\[datasetTable\] \<#datasetTable\>\__。
4.4.2.2. 视频伪造¶
视频伪造是深度伪造的一个重要分支,与对图像进行篡改不同,视频伪造需要考虑到视频的时序,不同主客体在画面上的相对位置变化、甚至更进一步的音频伪造等多个维度。Aliaksandr (Siarohin et al., 2019) 提出将视频的内容分为主体和动作,其中主体表示视频中出现的人物,而动作表示人物的行为。基于以上假设,Aliaksandr提出了动作驱动网络网络来生成视频。这个网络将一个随机向量序列映射成为一序列的视频帧,最后组成视频。每个向量包含表示主体的部分和表示动作的部分,在视频的生成过程中,表示主体的部分固定不变。它同时使用图片判别器和视频判别器来训练。
如何解决生成高分辨率伪造视频同样也是一个问题,Tian (Tian et al., 2021) 等人提出了一个框架MoCoGAN-HD,利用已有的图像生成器来渲染高分辨率视频。作者将视频合成问题看作是在预训练的图像生成器的潜在输出空间中寻找运动轨迹。这种框架不仅可以渲染高分辨率视频,而且计算效率也更高。作者引入了一种动作生成器,该生成器能够探查到我们期待的运动轨迹,使其中的主体和动作解耦。作者还引入了一项新的训练方法,即跨域视频合成,即图像和运动生成器在不同域的不相交数据集上进行训练,这样可以生成训练集中不存在的新视频内容。MoCoGAN-HD的结构如 图4.4.6 所示。
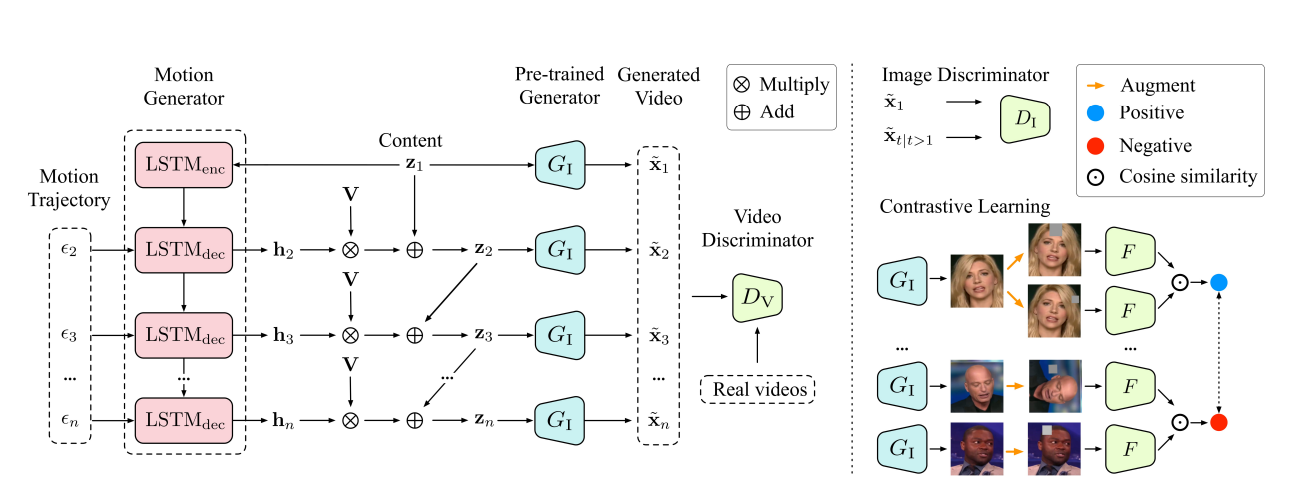
图4.4.6 MoCoGAN-HD的网络架构¶
与MoCoGAN-HD不同,Yu等人 (Yu et al., 2022) 将隐式神经表示(Implicit Neural Representation,INR)将连续信号编码到参数化神经网络中,从另一个维度来解决现阶段生成高质量长视频的一些问题。于是,Yu等 人 (Yu et al., 2022) 提出了DI-GAN,这是一种利用视频的INR,结合动态感知的隐式生成对抗网络。具体而言,DI-GAN引入了基于INR的视频生成器 图4.4.7(a),通过以不同的方式操作空间和时间坐标来改善生成动作的质量,并能在不观察整个长序列视频帧的情况下高效识别非自然运动的动作鉴别器 图4.4.7(b)。
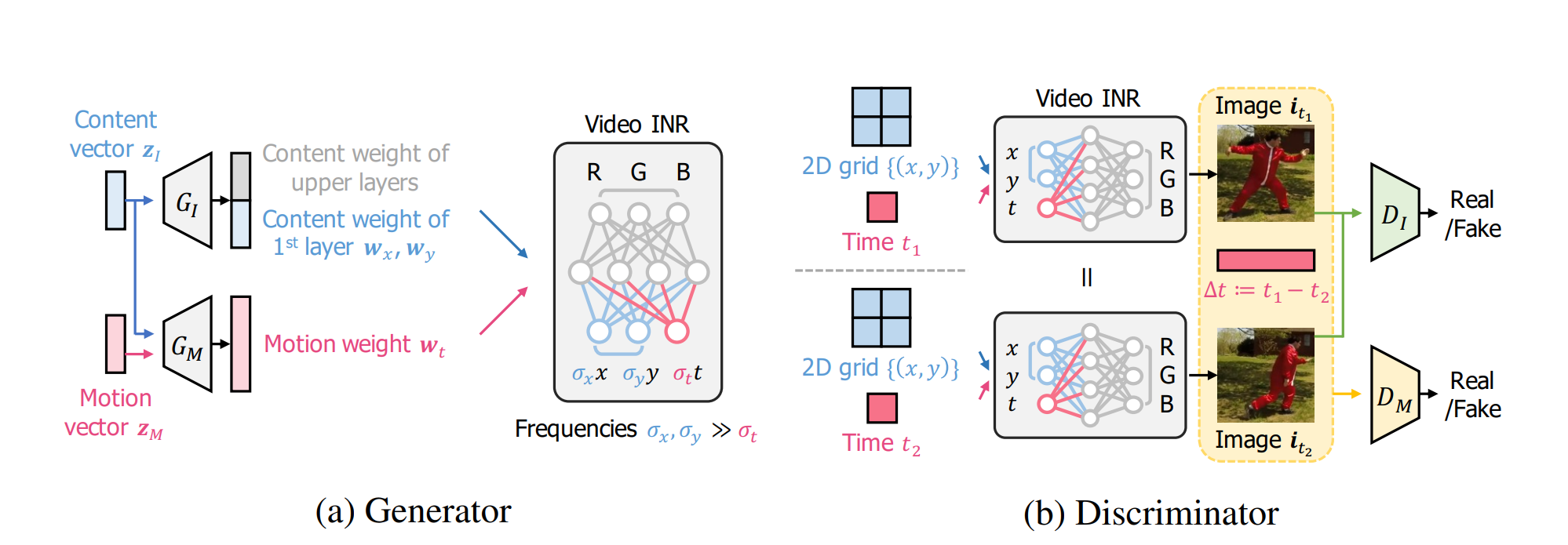
图4.4.7 DI-GAN的生成器与鉴别器¶
4.5. 本章小结¶
本章介绍了针对人工智能数据的四类常见攻击:数据投毒(章节5.1)、隐私攻击(章节5.2)、数据窃取(章节5.3)和篡改与伪造(章节5.4)。其中,投毒攻击通过污染训练数据来阻碍模型的正常学习,我们总共介绍了六种不同的投毒方式及其攻击特点。隐私攻击在黑盒或白盒模型下对已训练好的目标模型进行访问,通过模型的记忆特性反推有关训练数据的隐私信息,我们介绍了成员推理攻击、属性推理攻击以及其他推理攻击。数据窃取相较隐私攻击更近一步,直接逆向模型的原始训练数据。与前三种攻击不同,篡改与伪造是一种技术滥用而不是针对技术本身的攻击,其中包括普通篡改和深度伪造,前者通过编辑和修改各类图像来生成伪造数据,而后者则更加关注于人脸图像的伪造。实际上,当前人工智能的数据收集和使用方式所引发的担忧长期以来一直存在,而深度学习的迅速发展又加重了这些担忧,因为技术越先进影响的人就会越多。对此,我们需要不断地提出更新更高效的防御技术来防止敏感信息和原始数据的泄露和滥用。